Dependiendo del primer byte de una dirección IP es posible identificar de qué clase se trata:
Clase A: diseñada para dar cabida a redes extremadamente grandes. El primer bit de un dirección de Clase A es siempre un 0. Puede soportar 16 777 214 (\(2^{24} -2\) ) direcciones de host únicas, siendo el rango desde la 1.0.0.0 a la 126.0.0.0. Utiliza el primer byte para definir la red y los tres restantes para el host. Teóricamente la 127.0.0.0 también es una dirección clase A pero está reservada para la dirección de loopback.
Clase B: para redes de tamaño moderado a grande. Los dos primeros bits de un dirección de Clase B son 10, por tanto van desde las direcciones 128.0.0.0 a la 191.0.0.0. Al utilizar los dos primeros bytes como campo de red, da cabida para 65 534 hots (\(2^{16}-2\) ) y pueden definirse 16 382 redes diferentes (\(2^{14} -2\) ).
Clase C: para muchas redes y pequeñas. Los tres primeros bits de una dirección de clase C son 110, por tanto parten de la dirección 192 (128+64). El rango de redes va de 192.0.1.0 a 223.255.254.0.
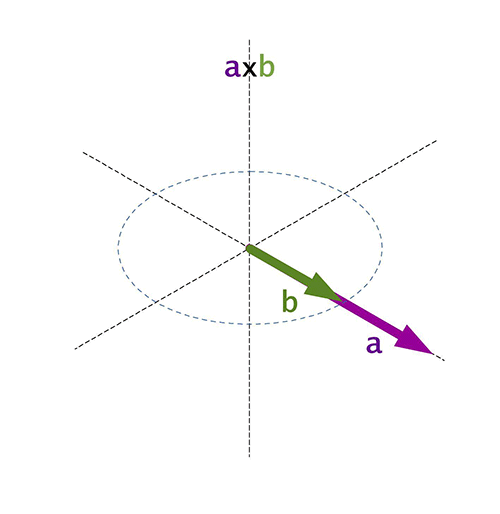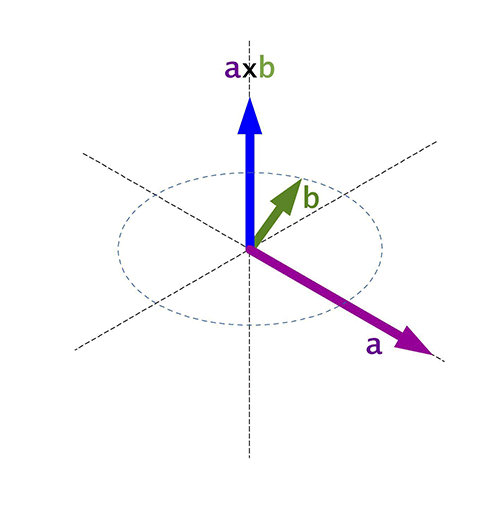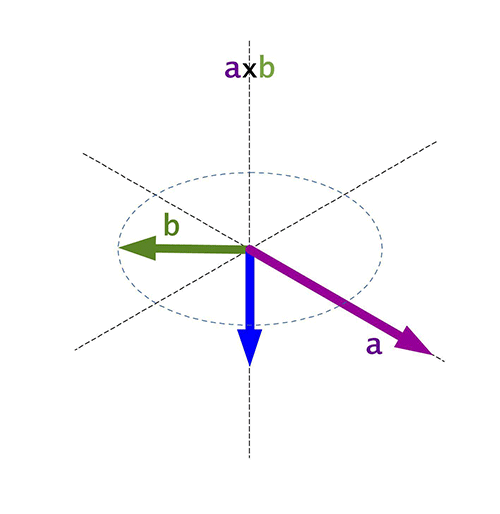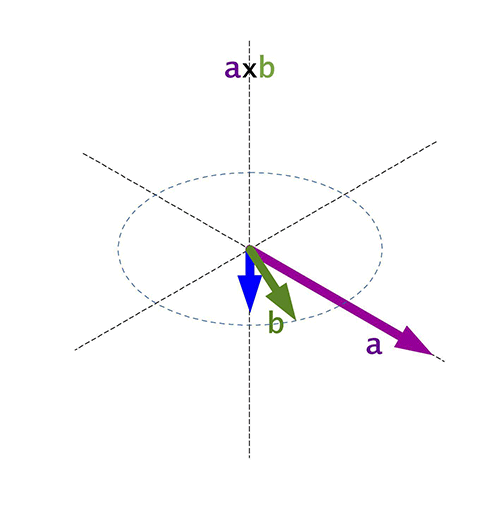
En siguientes entradas vamos a hablar de la polarización de las ondas electromagnéticas radiadas por antenas. Es por ello que es útil tener presentes las propiedades del producto vectorial.
Nota: la notación \(\mathbf{a}\) significa vector.
Algunas de las propiedades más importantes son:
\(\mathbf{a} \times \mathbf{b} = 0 \) si \(\mathbf{a} = 0\) ó \(\mathbf{b} = 0\) ó \(\mathbf{a} \| \mathbf{b}\)
El producto vectorial es nulo si uno de los dos vectores es 0 o si por el contrario, ambos vectores son perpendiculares.
Para calcular el módulo del producto vectorial, se puede multiplicar el módulo de ambos vectores por el seno del menor ángulo entre ambos vectores.
\(\hat{\mathbf n}\) es el vector unitario perpendicular a \(\mathbf{a}\) y \(\mathbf{b}\).
\[\hat{\mathbf n} = \frac{ \mathbf a \times \mathbf b }{|\mathbf a \times \mathbf b|}\]
Para calcular el valor del producto vectorial:
\[\mathbf w = \mathbf u \times \mathbf v = \begin{vmatrix} \mathbf i & \mathbf j & \mathbf k \\ u_x & u_y & u_z \\ v_x & v_y & v_z \\ \end{vmatrix} = \begin{vmatrix} u_y & u_z \\ v_y & v_z \\ \end{vmatrix} \cdot \mathbf i – \begin{vmatrix} u_x & u_z \\ v_x & v_z \\ \end{vmatrix} \cdot \mathbf j + \begin{vmatrix} u_x & u_y \\ v_x & v_y \\ \end{vmatrix} \cdot \mathbf k\]
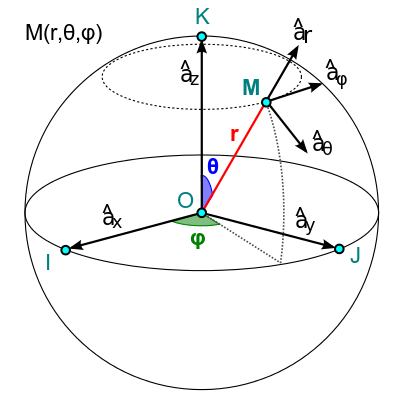
Si estamos tratando con coordenadas polares, como suele suceder en radiación, los vectores directores de \(\theta\), \(\phi\) y \(r\) son los que aparecen en la imagen. Una manera sencilla de recordar su dirección es la siguiente: dado un punto cualquiera del espacio, los vectores directores de \(\theta\), \(\phi\) y \(r\) apuntan en las direcciones en las que \(\theta\), \(\phi\) y \(r\)aumentan. Por lo tanto:
Donde podríamos equiparar \(\hat{r}\) con \(\hat{x}\), \(\hat{\theta}\) con \(\hat{y}\) y \(\hat{\phi}\) con \(\hat{z}\)
de manera que:
\(\hat{x}\) \(\hat{r}\)
\(\hat{y}\) \(\hat{\theta}\)
\(\hat{z}\) \(\hat{\phi}\)
el producto de izquierda a derecha, siempre da como resultado el siguiente valor de la derecha con signo dando la vuelta por los extremos de la tabla y en sentido contrario, el signo negativo.
Puede ser bastante interesante saber cómo poder poder representar gráficamente el espectro de frecuencia un archivo de audio con MATLAB.
Para transformar una función del dominio temporal al frecuencial, es necesario hacer la transformada de Fourier de dicha función. En el caso de una señal contínua la transformada recibe el nombre de Transformada de Fourier mientras que si es de caracter discreto o digital, se le conoce como DFT (Discrete Fourier Transform).
En MATLAB, calcular la transformada de Fourier es tan sencillo como utilizar la funcion FFT (Fast Fourier Transform). Sin embargo, quizá no sea del todo claro cómo se ha de escoger el eje de coordenadas frecuenciales (eje X) para obtener una representación adecuada.
audio = audioread('audio.wav');
Fs = 16000;
L = length(audio);
NFFT = 2^nextpow2(L);
Y = fft(audio, NFFT)/L;
f = Fs/2*linspace(0,1,NFFT/2+1);
plot(f, 2*abs(Y(1:NFFT/2+1);
Comentemos línea a línea su significado.
audio = audioread('audio.wav');
Cargamos el archivo de audio en una variable llamada ‘audio’ de MATLAB.
Fs = 16000;
Introducimos la frecuencia de muestreo a la cual ha sido adquirido el audio. Es de vital importancia saber este parámetro, ya que de lo contrario no podremos identificar las frecuencias. Si por ejemplo has grabado el audio con un móvil, muchas aplicaciones permiten seleccionar la frecuencia de muestreo. Típicamente la frecuencia de muestro en un móvil es de 16 kHz, aunque para aseguraros podéis abrir el archivo con Audacity y os indicará la frecuencia de muestreo.
L = length(audio);
Calculamos el número de muestras que contiene el audio y lo guardamos en la variable L.
NFFT = 2^nextpow2(L);
La función fft() es más eficiente cuando calcula la transformada de Fourier de una función cuya longitud es una potencia de 2 (2, 4, 8, …). Por este motivo, vamos a calcular cuál es la potencia de 2 más próxima al número de muestras que contiene el audio. Si el archivo tiene 6 muestras, el número que le pasaremos a la función fft será 8, para que sea más eficiente. A este número lo llamaremos NFFT. Hay que tener en cuenta que este número será mayor que el número de muestras que contiene el archivo. Sin embargo, esto no afectará al resultado ya que las muestras que faltan son interpretadas como 0. De esta manera no añaden ningún contenido frecuencial al archivo original.
Y = fft(audio, NFFT)/L;
Calculamos la FFT con la función fft() cuyos argumentos son el audio que queremos transformar (audio), y el número de muestras sobre la que queremos que haga la transformada (NFFT). Dividimos entre L el resultado para normalizar los valores. La transformada la tendremos en la variable Y.
f = Fs/2*linspace(0,1,NFFT/2+1);
Ahora toca construir el eje de coordenadas. Las frecuencia que devuelve la FFt van de la frecuencia 0 hasta la frecuencia mitad de la frecuencia de muestreo \(\frac{F_s}{2}\) . Por tanto, necesitamos generar un vector que vaya desde 0 hasta \(\frac{F_s}{2}\). El número de elementos que este vector debe de contener es \(\frac{NFFT}{2}+1\) ya que debido a que la DFT genera una imagen espejo del espectro de frecuencia, solo querremos visualizar la mitad.
plot(f, 2*abs(Y(1:NFFT/2+1)));
Por último generamos la gráfica cuyo eje de coordenadas está contenido en la variable f y cuyo eje de ordenadas es 2 veces el valor absoluto (para mostrar solo la magnitud y no la parte real e imaginaria) de la mitad del espectro.
También podéis descargar el script audio_fft.m que he creado con función llamada audio_fft(audio, Fs) donde todo esto está ya encapsulado y que podéis descargar pulsando el enlace. Un ejemplo de uso sería:
audio_fft('archivo.wav', 16000);
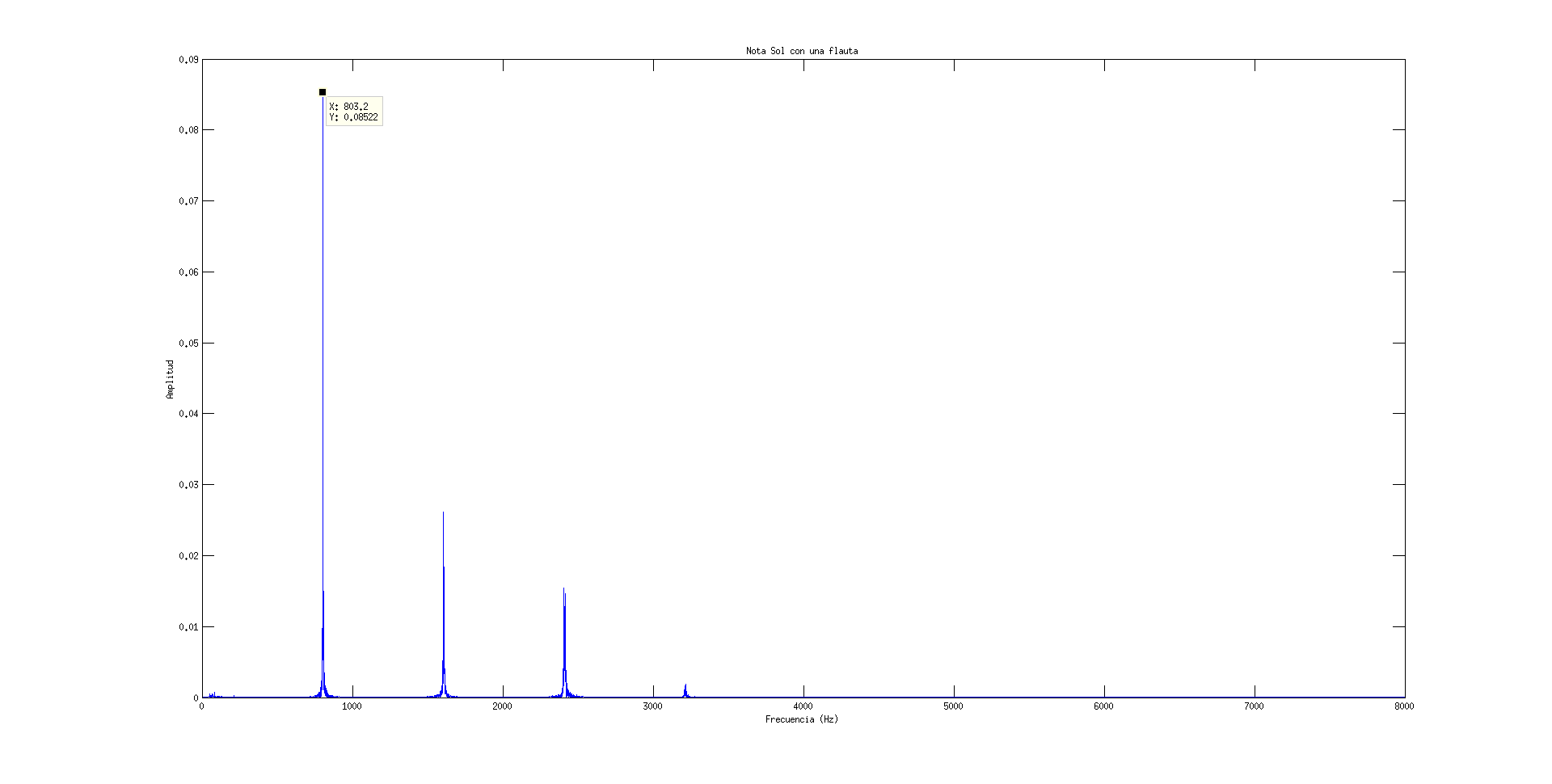
Como ejemplo he grabado un Sol con una flauta celta y he calculado el espectro frecuencial. El sonido es el siguiente:
Y el resultado es el siguiente:
Donde se puede apreciar claramente la frecuencia fundamental y sus armónicos.
Gracias a los bots de Telegram, es sencillo interaccionar entre Telegram y una Raspberry. La idea es la siguiente:
Desde la aplicación de Telegram, enviaremos un comando al servidor de Telegram. Se puede configurar mediante webhooks que redireccione este mensaje a un servidor propio con SSL, tal y como expliqué en una entrada anterior.. Este servidor con SSL reenviará la información a otro servidor montado sobre la Raspberry. En la Raspberry, recibiremos las notificaciones enviadas por el usuario. Para conseguir que el que el servidor con cifrado SSL consiga enviar a nuestra Raspberry la información, será necesario configurar la Raspberry con un IP estática y utilizar un servidor de DNS dinámicas, configurar nuestro router de casa para redireccionar todas las peticiones provinientes del exterior (de Internet) en el puerto 80 al puerto 80 de nuestra Raspberry. Este paso quizá sea el más complicado debido a la cantidad de pasos que hay que hacer, sin embargo es posible.
Sería posible utilizar un solo servidor para entregar el comando de Telegram directamente sobre la Raspberry. Sin embargo, es necesario que el servidor de la Raspberry cuente con un certificado SSL. La API de Telegram permite utilizar certificados autofirmados, sin embargo yo no lo he probado ya que disponía en el servidor de un certificado SSL de Let’s Encrypt.
En el servidor con SSL el código del archivo PHP es:
<?php
$bottoken = "myToken";
$website = "https://api.telegram.org/bot".$bottoken;
$update = file_get_contents('php://input');
$update = json_decode($update, TRUE);
$chatId = $update["message"]["chat"]["id"];
$message = $update["message"]["text"];
switch($message) {
case "/radio":
$result = file_get_contents('http://raspberryLocation/test.php');
if(!strcmp($result, "Encendido"))
sendMessage($chatId, "Enchufando radio");
else
sendMessage($chatId, "Apagando radio");
break;
case "/temperatura1":
sendMessage($chatId, "La temperatura es de 18 ºC");
break;
default:
sendMessage($chatId, "default");
}
function sendMessage ($chatId, $message) {
$url = $GLOBALS['website']."/sendMessage?chat_id=".$chatId."&text=".urlencode($message);
file_get_contents($url);
}
?>
Para interactuar con los pines GPIO de la Raspberry, es necesario utilizar la librería WiringPi. El principal problema que existe con esta librería es que se necesitan permisos de super usuario para poder utilizarla. Para hacer una prueba rápida, le he dado permisos de superusuario al usuario www-data, que es el que ejecuta los archivos PHP. Sin embargo, esto es potencialmente peligroso. En cuanto encuentre una solución la subiré.
En mi prueba, he hecho que al enviar un comando desde Telegram, ponga a nivel alto o bajo un pin GPIO. El script que corre en el servidor de la Raspberry cuenta de dos partes. Una escrita en C que se encarga de interaccionar con la libreria WiringPi y otra en PHP que ejecuta el programa en C propio para cada comando.
La parte de PHP es la siguiente (archivo test.php que es llamado por el servidor con SSL):
El programa en C es el que se ejecuta con la instrucción exec() es el siguiente:
#include <stdio.h> // Used for printf() statements
#include <wiringPi.h> // Include WiringPi library!
#include <fcntl.h> //File management
#include <unistd.h> //File checker
// Pin number declarations. We're using the Broadcom chip pin numbers.
const int radioPin = 4; // Radio pin
char radio[] = "radio";
int main(void)
{
wiringPiSetupGpio(); // Initializa wiringPi -- utilizando los números de pines de Broadcom
pinMode(radioPin, OUTPUT);
FILE *fp;
if(access(radio, F_OK) != -1){
// file exists
printf("Apagado");
remove(radio);
digitalWrite(radioPin, LOW);
} else {
// file doesn't exist
printf("Encendido");
fp = fopen(radio, "w+");
fclose(fp);
digitalWrite(radioPin, HIGH);
}
return 0;
}
Este programa es muy sencillo y simplemente comprueba que exista un archivo llamado radio en la carpeta donde se encuentra. Si el archivo existe, entonces quiere decir que la radio estaba encendida y por tanto elimina el archivo y apaga la radio. Si el archivo no existe, la radio estaba apagada y enciende la radio poniendo el pin a nivel alto y crea el archivo radio.
Para compilar este programa es necesario utilizar la siguiente instrucción:
gcc -Wall -o switch switch.c -lwiringPi
Es posible que sea necesario ejecutar el compilador gcc como superusuario añadiendo sudo si estáis en la carpeta del servidor (es decir /var/www).
De esta manera, es posible encender y apagar un relé, por ejemplo, si conectamos el pin en cuestión a la Raspberry. Por tanto, estaríamos controlando una lampara, una luz o una radio.
Desde el año pasado, Telegram permite crear bots para poder interaccionar con un servidor de manera automática.
La manera de crear un bot se realiza a través del BotFather, un bot de Telegram que permite crear el tuyo propio. Una vez hayamos creado nuestro bot, BotFather nos dará un token. Este token es un identificador único que solo debes saber tú ya que te dará acceso a realizar cualquier acción sobre tu bot.
Una vez creado el bot, podemos enviarle mensajes, sin embargo, nadie contestará. Existen dos maneras para acceder a los mensajes que se hayan enviado por un usuario. La primera es mediante el método getUpdates, que básicamente consiste en una escucha activa mediante un bucle para detectar que alguien nos ha enviado un mensaje. Para comprobar rápidamente que los mensajes no están llegando, podemos pegar esta URL en el navegador, cambiando MYTOKEN por nuestro token real:
https://api.telegram.org/botMYTOKEN/getUpdates
De esta manera podremos ver qué mensajes están pendientes de ser respondidos.
Para responder desde el navegador, podemos utilizar el método sendMessage:
En el que tendremos que cambiar MYTOKEN por nuestro token, CHATID por el ID del chat al cual queramos respondes y que habremos obtenido del método getUpdates (ver captura anterior), y TEXT por el texto que queramos enviar.
Sin embargo, con este método ya se ve que no es demasiado cómodo utilizar un bot de Telegram.
La mejor opción es utilizar un webhook. Un webhook es un archivo PHP (o cualquier otro lenguaje que podamos correr en nuestro servidor como Python, Ruby o Java) en el que cada vez que alguien envíe un mensaje a nuestro bot, Telegram hará una llamada automática a este archivo.
De esta manera podremos automatizar totalmente la interacción con nuestro bot.
Para decirle a Telegram dónde se encuentra nuestro webhook, es necesario ejecutar la siguiente URL:
Es muy importante que nuestro servidor tenga cifrado SSL para poder hacer peticiones HTTPS sobre él. Si no dispones de uno, te recomiendo que instales el certificado de Let’s Encrypt, el cual permite crear un certificado SSL de manera totalmente gratuita. Si por el contrario tienes un certificado autofirmado, Telegram te explica como enviarles tu clave pública del certificado.
El código PHP que he utilizado para mi bot es el siguiente:
rsync es una herramienta para copiar archivos que es de gran utilidad cuando el número de archivos es bastante elevado. De esta manera podemos realizar copias de seguridad de manera mucho más rápida que a través de FTP o SFTP.
Para ello, necesitaremos hacer login a través de SSH. Cuando el puerto SSH no sea el predeterminado, lo podemos indicar de la siguiente manera
Una manera sencilla de realizar FFT desde cualquier sistema operativo sin necesidad de disponer de programas como MATLAB, Octave o Mathematica, es utilizando un script de Python. Este lenguaje cuenta con la ventaja de ser muy sencillo y además de disponer una ingente cantidad de librerías para poder hacer casi cualquier cosa.
El objetivo de este pequeño programa es realizar una FFT de un trozo de audio grabado directamente desde un micrófono. Para ello se realiza una escucha pasiva a la espera de un sonido cuyo volumen esté por encima de un determinado umbral. Este umbral se puede modificar con la variable threshold, y dependiendo del micrófono y su sensibilidad debe de ser ajustado de manera diferente. Una vez detectado, se graba unos pocos segundos de audio, cuya longitud puede ser modificada en el segundo bucle for. Actualmente graba aproximadamente 1 segundo, pero si se cambia el 7 por un 100 la longitud es de 13 segundos.
El audio se guarda como un archivo para ser posteriormente utilizado en el cálculo de la FFT y ser graficada al momento. Todo este procedimiento está dentro de un bucle infinito, por lo que, aunque la ventana de la gráfica es bloqueante, está continuamente escuchando.
Las librerías necesarias para poder ejecutar este script son: numpy, matplotlib, pyaudio y scipy.
#!/usr/bin/python
# -*- coding: utf-8 -*-
import pyaudio
import struct
import math
import wave
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
#import urllib
#import urllib2
import os
class Microphone:
def rms(self,frame):
count = len(frame)/2
format = "%dh"%(count)
shorts = struct.unpack( format, frame )
sum_squares = 0.0
for sample in shorts:
n = sample * (1.0/32768.0)
sum_squares += n*n
rms = math.pow(sum_squares/count,0.5);
return rms * 1000
def passiveListen(self,persona):
CHUNK = 1024; RATE = 8000; THRESHOLD = 200; LISTEN_TIME = 5
didDetect = False
# prepare recording stream
p = pyaudio.PyAudio()
stream = p.open(format=pyaudio.paInt16, channels=1, rate=RATE, input=True, frames_per_buffer=CHUNK)
# stores the audio data
all =[]
# starts passive listening for disturbances
print RATE / CHUNK * LISTEN_TIME
for i in range(0, RATE / CHUNK * LISTEN_TIME):
input = stream.read(CHUNK)
rms_value = self.rms(input)
print rms_value
if (rms_value < THRESHOLD):
didDetect = True
print "Listening...\n"
break
if not didDetect:
stream.stop_stream()
stream.close()
return False
# append all the chunks
all.append(input)
for i in range(0, 7):
data = stream.read(CHUNK)
all.append(data)
# save the audio data
data = ''.join(all)
stream.stop_stream()
stream.close()
wf = wave.open('audio.wav', 'wb')
wf.setnchannels(1)
wf.setsampwidth(p.get_sample_size(pyaudio.paInt16))
wf.setframerate(RATE)
wf.writeframes(data)
wf.close()
return True
if __name__ == '__main__':
mic = Microphone()
while True:
if mic.passiveListen('ok Google'):
fs, data = wavfile.read('audio.wav')
L = len(data)
c = np.fft.fft(data) # create a list of complex number
freq = np.fft.fftfreq(L)
#freq = np.linspace(0, 1/(2L), L/2)
print freq
freq_in_hertz = abs(freq * fs)
plt.plot(freq_in_hertz, abs(c))
plt.show()
¿Cuantas veces hemos ejecutado el siguiente comando desde el terminal de Linux?
$ ls -l
Lo que hace el sistema operativo es buscar un binario llamado “ls” y lo ejecuta. Las carpetas donde busca son las que componen la variable $PATH, que por defecto algunas carpetas como /etc, /bin ya forman parte de $PATH. Si queremos añadir una carpeta distinta que las que hay por defecto, lo que podemos hacer es:
$ gedit ~/.bashrc
Nota: dependiendo del shell de Linux que utilices, el fichero que hay que editar será diferente. En sistemas operativos comunes como Ubuntu, el shell por defecto es bash. También existen zsh o csh para los cuales el archivo que se ejecuta al iniciar un nuevo terminal es ~/.zshrc y ~/.cshrc respectivamente.
Una vez gedit se haya abierto, si queremos añadir una única carpeta, simplemente pegamos la siguiente línea al final del archivo:
Una vez guardado, cerramos gedit, cerramos el terminal y volvemos a abrir otro.
Ahora al ejecutar
$ echo $PATH
aparecerá la carpeta que hemos acabado de añadir, con lo que podremos ejecutar cualquier archivo ejecutable que haya dentro sin tener que especificar la ruta.
La decodificación MAP es aquella en la que se decide qué símbolo ha sido transmitido en función de la probabilidad a posteriori, es decir \(P\left(x_i | y_j \right)\) o la probabilidad condicional de que si se ha recibido \(y_j\), se haya transmitido \(x_i\). Dicho de otro modo, ¿cuál es el símbolo más probable que la fuente haya podido enviar \(x_i\) si yo he recibido \(y_j\)? Aquel de todos los posibles símbolos que se hayan podido transmitir cuya probabilidad a posteriori sea máxima, será el que se decida como transmitido.
Pero sin embargo, para poder determinar esta probabilidad, al decodificador se le tiene que pasar la información del canal. En lugar de recibir del canal directamente si se ha enviado un 1 ó un 0 (salida hard), el decodificador tiene como entrada la información del espacio de la señal, es decir, con el valor analógico de la salida del canal. De esta manera el decodificador dispone de mayor información para tomar la decisión de cuál ha sido el código transmitido. Este valor representa una medida de la fiabilidad con la que es tomado cada símbolo y se conoce como un codificador con entrada soft.
Un modo de calcular estas probabilidades a posteriori de manera computacionalmente eficiente, es mediante el algoritmo BCJR (ideado por Bahl, Cocke, Jelinek y Raviv en el 1974). El algoritmo BCJR permite la obtenención de las LLR a posteriori (Log Likelihood Ratio) por bit (\(x_i\) binario):
\[LLR \left( x_i | y \right) = \ln{\frac{P \left( x_i = 1 | y \right) }{P \left( x_i = 0 | y \right)}}\]
Mediante el uso de la LLR, si la probabilidad de haber transmitido \(x_i = 1\) habiendo recibido y es mayor que la de haber transmitido \(x_i = 0\), el valor del logaritmo es positivo y negativo al contrario. Por eso, es más sencillo mirar el signo de la operación, que comparar directamente el valor absoluto de los dos valores.
A diferencia del algoritmo de Viterbi, el BCJR calcula de manera diferente cuál ha sido el bit más probable que se ha podido transmitir. Viterbi calculaba decisiones hard a partir de la detección de la secuencia de símbolos más probable, es decir, aquella que supusiera un recorrido cuya distancia a través del Trellis fuera de menor distancia. Sin embargo, el algoritmo BCJR calcula información soft. Por tanto, mientras que el algoritmo de Viterbi produce la secuencia de símbolos más probable que minimiza la probabilidad de error por secuencia, el algoritmo BCJR minimiza la tasa de error media por símbolo. Esta sutil diferencia hace que la detección de códigos mediante BCJR sea más ventajosa que utilizando el algoritmo de Viterbi.
Ambos algoritmos comparten similitudes ya que ambos están basados en el mismo diagrama de Trellis, ambos asignan una métrica a cada transición y ambos recorren el diagrama de trellis recursivamente. Sin embargo, en lugar de pasar de principio a final como hace Viterbi, en el algoritmo BCJR se realizan dos pasadas: de izquierda a derecha y de derecha a izquierda.
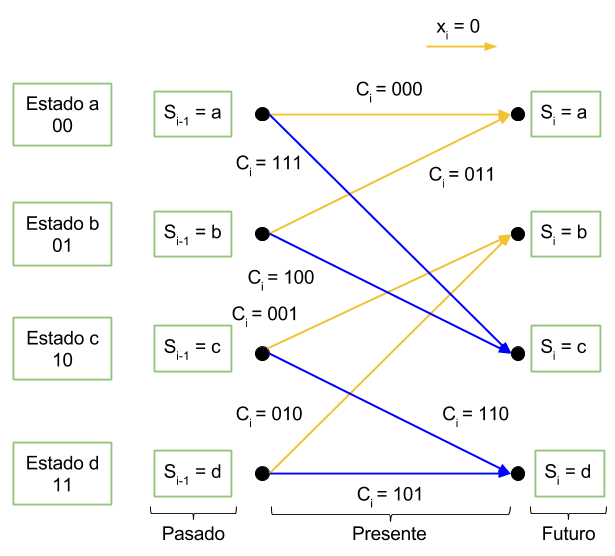
Revisando el diagrama de trellis
Imaginemos que estamos en la etapa i de un diagrama de trellis cualquiera tal y como aparece en la figura. En el diagrama de trellis podemos definir el dato que entrega el canal como \(y_i\). El estado antes de la transición como \(S_{i-1}\) y el diagrama después de la transición como \(S_i\).
La clave del algoritmo BCJR es la descomposición de la probabilidad a posteriori para una transición en tres factores: el primero dependiendo de las observaciones pasadas, el segundo dependiendo de observaciones presentes y el tercero atendiendo a observaciones futuras. Cabe destacar que cuando se aplica el algoritmo BCJR el receptor ya dispone de la trama completa de datos, por lo que es posible separar entre pasado, presente y futuro. Es decir, dado un bit en la posición i, el algoritmo sí tiene acceso a los bits que se enviaron después de él. No es un algoritmo que se aplica al vuelo conforme llegan bits.
La decodificación de un símbolo mediante el criterio MAP viene dada por:
\[hat{x}_i = \max_{x_i \in \left \{ \text{M simbolos} \right \} }{ \{ P\left( x_i | y \right) \}} = \left \{ \text{Teorema de Bayes} \right \} = \\ \max_{x_i \in \left \{ \text{M simbolos} \right \} }{ \frac{ p \left( x_i, y \right) }{ p \left( y \right) } } = \left \{ p \left( y \right) \text{ constante} \right \} = \\ \max_{x_i \in \left \{ \text{M simbolos} \right \} }{ \{ p \left( x_i, y \right) \} } = \max_{l \in \left \{ 0, 1, …, M -1 \right \} }{\sum_{\left( S_{i-1}, S_i \right) \in S^l } p\left( S_{i-1}, S_i, y \right) } donde l \in \left \{ 0, 1, …, M -1 \right \}\]
son todos los posibles símbolos \(y \left( S_{i-1}, S_i \right) \in S^l\) son las posibles transiciones que salen de cada estado cuando se envía el símbolo l. Por ejemplo, en una comunicación binario los únicos símbolos son 0 y 1 (es decir \(l \in \left \{ 0, 1 \right \}\) que en este caso se llaman bits). Por tanto, de cada estado que tenga el decodificador saldrán dos posibles transiciones. Una debida a la recepción del bit 0 y otra al bit 1. El conjunto de transiciones que ocurren cuando se recibe un 0 se denominan \(S^0\) y las transiciones que ocurren cuando al decodificador entra un 1 se denominan \(S^1\).
Por tanto, de la ecuación \(\ref{eq:limite}\) podemos interpretar que para estimar el símbolo \(\hat{x}_i\) con mayor probabilidad de haber sido enviado, hay que encontrar la suma de las probabilidades conjuntas de estar en el estado \(S_{i-1}\), ir al estado \(S_i\) y haber recibido los datos y para cada uno de los símbolos. Aquel símbolo que de una suma mayor, será el elegido como \(\hat{x}_i\).
Como hemos dicho antes, podemos descomponer el diagrama de estados en tres: pasado, presente y futuro. De este modo, los datos recibidos y se pueden descomponer como los datos recibidos en el pasado, el bit recibido en el presente y los bits que me llegarán en el futuro.
\(\mathbf{y}=\left [ \left ( y_1~y_2~…~y_{i-1} \right ), y_i, \left (y_{i+1}~y_{i+2}~…~y_{N} \right ) \right ] = \left[ \mathbf{y}_1^{i-1}, y_i, \mathbf{y}_{i+1}^N \right] \) donde \(\mathbf{y}_1^{i-1}\) representa a los datos recibidos en el pasado, \(y_i\) es el dato que recibo en el presente y \(\mathbf{y}_{i+1}^N\) son los datos que recibiré en el futuro. El subíndice 1 indica pasado, el i indica presente y el i+1 indica futuro. Así mismo, el superíndice i-1 indica la dimensión del vector. En el caso de los datos pasados el vector tendrá una dimensión desde 1 hasta i-1 (por tanto dimensión i-1). Para el caso de los datos futuros, la dimensión va desde i+1 hasta N, que es el número de símbolos enviados (o bits si la señal es binaria).
Ahora, a partir de la interpretación que hemos hecho arriba de la función densidad de probabilidad \(p\left( S_{i-1}, S_i, y \right)\), podemos aplicar el teorema de Bayes repetidas veces para conseguir una función equivalente pero separada en varios trozos.
A modo de recordatorio:
\[p\left( a, b \right) = p \left(a | b\right) p \left( b \right)\]
\[p\left( a, b, c \right) = p \left(a | b, c\right) p \left( b, c \right)\]
\[p\left( a, b, c, d \right) = p \left(a, b | c, d\right) p \left(c, d \right)\]
Teniendo en cuenta esto, podemos reescribir la función \(p\left( S_{i-1}, S_i, y \right)\) como, \(p\left( S_{i-1}, S_i, \mathbf{y} \right) = p \left( S_{i-1}, S_i, \mathbf{y}_1^{i-1}, y_i, \mathbf{y}_{i+1}^N \right)= p \left(\mathbf{y}_{i+1}^N | S_{i-1}, S_i, \mathbf{y}_1^{i-1}, y_i \right) p \left( S_{i-1}, S_i, \mathbf{y}_1^{i-1}, y_i \right) \)
En \(\ref{eq:prob_states_1}\) hemos descompuesto los datos recibidos en pasado, presente y futuro. Después hemos escrito la misma función utilizando la probabilidad condicionada de los datos futuros \(\mathbf{y}_{i+1}^N\). Ahora volvemos a aplicar la probabilidad condicionada en el factor \(p \left( S_{i-1}, S_i, \mathbf{y}_1^{i-1}, y_i \right)\) pero esta vez evaluando la expresión a llegar al estado \(S_i\) y que el dato sea \(y_i\) si estábamos en el estado \(S_{i-1}\) y los datos pasados son \(y_1^{i-1}\). \(p \left(\mathbf{y}_{i+1}^N | S_{i-1}, S_i, \mathbf{y}_1^{i-1}, y_i \right) p \left( S_{i-1}, S_i, \mathbf{y}_1^{i-1}, y_i \right) = \\ p \left(\mathbf{y}_{i+1}^N | S_{i-1}, S_i, \mathbf{y}_1^{i-1}, y_i \right) p \left(S_i, y_i | S_{i-1}, \mathbf{y}_1^{i-1} \right)p \left(S_{i-1}, \mathbf{y}_1^{i-1} \right)\)
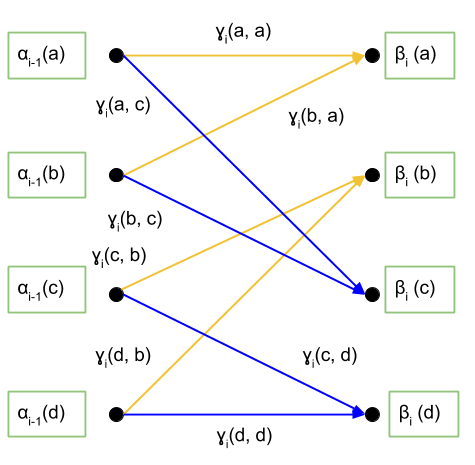
Ahora fijémonos en cada término: \(p \left(S_{i-1}, \mathbf{y}_1^{i-1} \right)\): es la probabilidad conjunta de haber estado en el estado \(S_{i-1}\) y que los datos anteriores fueran \(\mathbf{y}_1^{i-1}\). A esta expresión la vamos a llamar \(\alpha_{i-1} \left( S_{i-1} \right)\).
\(p \left(S_i, y_i | S_{i-1}, \mathbf{y}_1^{i-1} \right)\): es la probabilidad de llegar al estado \(S_i\) con el símbolo \(y_i\) sabiendo que estábamos en el estado \(S_{i-1}\) y que se habían enviado anteriormente \(y_1^{i-1}\). Obviamente, los datos que se habían enviado anteriormente no van a afectar en dónde estaré posteriormente si ya sé que estaba en \(S_{i-1}\). Una analogía fácil para visualizar este hecho es el siguiente: yo estoy en el punto A. Desde este punto tengo dos caminos que puedo elegir: el camino 1 y el camino 0. Para determinar si voy a terminar en el punto B o no, me da exactamente igual saber qué camino escogí para llegar al punto A. Solo me importa donde estoy, dónde voy y qué caminos tengo para elegir en ese momento. Por tanto, la expresión \(p \left(S_i, y_i | S_{i-1}, \mathbf{y}_1^{i-1} \right)\) se puede simplificar como \(p \left(S_i, y_i | S_{i-1}\right)\). A esta expresión la vamos a llamar \(\gamma_{i} \left( S_{i-1}, S_i \right)\).
\(p \left(\mathbf{y}_{i+1}^N | S_{i-1}, S_i, \mathbf{y}_1^{i-1}, y_i \right)\): siguiendo la analogía anterior, esta expresión representa cuál es la probabilidad de que escoja en el futuro una serie de caminos si ya sé dónde estoy, dónde estuve anteriormente, los caminos que escogí en el pasado y el camino que he cogido para llegar a dónde estoy ahora mismo. En este caso, poco importa saber dónde estuve hace tiempo, saber cómo llegué allí o cómo he llegado a donde estoy, ya que solo saber dónde estoy ahora mismo (\(S_i\)) me da información de adónde puedo ir \(\mathbf{y}_{i+1}^N\), cuáles serán los bits que me pueden llegar en el futuro). Por tanto, esta expresión la podemos simplificar como \(p \left(\mathbf{y}_{i+1}^N | S_{i-1}, S_i, \mathbf{y}_1^{i-1}, y_i \right) = p \left(\mathbf{y}_{i+1}^N | S_i, y_i \right)\). A esta expresión la vamos a llamar \( \beta_{i} \left( S_{i} \right)\).
De esta forma podemos redefinir el diagrama de trellis como muestra la siguiente figura.
Para calcular \(P\left( x_i = 1 | \mathbf{y}\right)\) sería igual pero utilizando las otras transiciones. O también \(P\left( x_i = 1 | \mathbf{y}\right) = 1 – P\left( x_i = 0 | \mathbf{y}\right)\)
Cálculo de α
\[\alpha_i \left( S_i \right) = p \left(S_i, y_1^i \right ) =\sum_{S_{i-1}, S_i \in S}{p \left(S_{i-1}, S_i, \mathbf{y}_1^{i-1}, y_i \right)} = \\ = \sum_{S_{i-1}, S_i \in S}{p \left( S_i, y_i| S_{i-1}, \mathbf{y}_1^{i-1} \right)}p \left(S_{i-1}, \mathbf{y}_1^{i-1} \right) = \\ = \sum_{S_{i-1}, S_i \in S}{p \left( S_i, y_i| S_{i-1} \right )}\alpha_{i-1} \left(S_{i-1} \right) = \sum_{S_{i-1}, S_i \in S}{\alpha_{i-1} \left( S_i \right)}\gamma_{i} \left(S_{i-1}, S_i \right)\]
Donde \(1 \leq i \leq N\) y \(N\) el número de símbolos enviados. Como vemos es un cálculo recursivo, en el que necesitamos el valor del α anterior para calcular el siguiente.
Cálculo de β
\[\beta_{i-1} \left(S_{i-1} \right ) = p \left(\mathbf{y}_i^n |S_{i-1} \right ) = \sum_{S_{i-1}, S_i \in S}{p \left( y_i,\mathbf{y}_{i+1}^n, S_i |S_{i-1}\right )}= \\ =\sum_{S_{i-1}, S_i \in S}{p \left(\mathbf{y}_{i+1}^n | S_i, y_i, S_{i-1}\right ) p \left( S_i, y_i| S_{i-1}\right )} =\\=\sum_{S_{i-1}, S_i \in S}{p \left(\mathbf{y}_{i+1}^n | S_i\right ) p \left( S_i, y_i| S_{i-1}\right )} =\sum_{S_{i-1}, S_i \in S}{\beta \left(S_i\right ) \gamma_i\left( S_{i-1}, S_i\right )}\]
Cálculo de γ
\[\gamma_i \left(S_{i-1}, S_i \right ) = p \left(S_i, y_i | S_{i-1} \right ) =p \left(y_i | S_i, S_{i-1} \right ) p \left(S_i | S_{i-1} \right) = p \left(y_i | c_i \right ) p \left( x_i \right )\]
Como podemos ver y era de esperar, el parámetro \(\gamma\) depende del canal, ya que \(p \left(y_i | c_i \right )\) es la función de verosimilitud que caracteriza el canal. En caso de ser un canal gaussiano, la \(p \left(y_i | c_i \right ) = \frac{1}{\sigma^2 \sqrt{\pi}} \cdot e^{- \frac{\left| y_i – c_i \right|^2}{2\sigma^2} }\)

{kind=link}
{kind=link}
{kind=link}