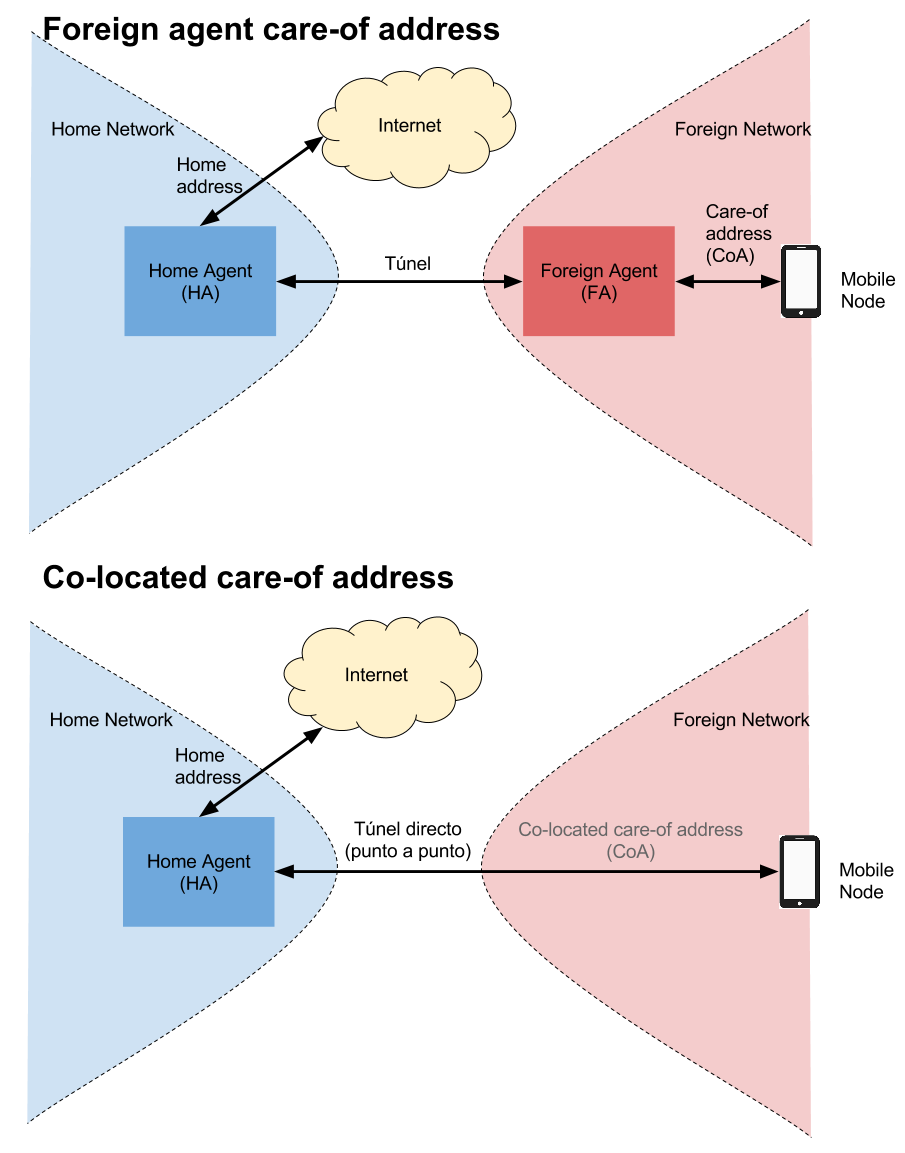
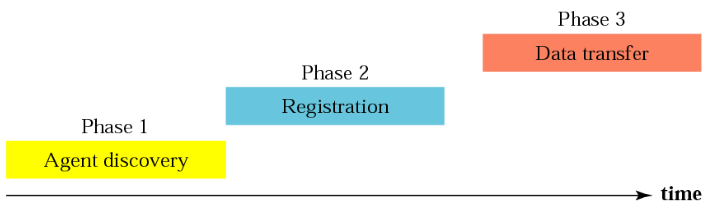
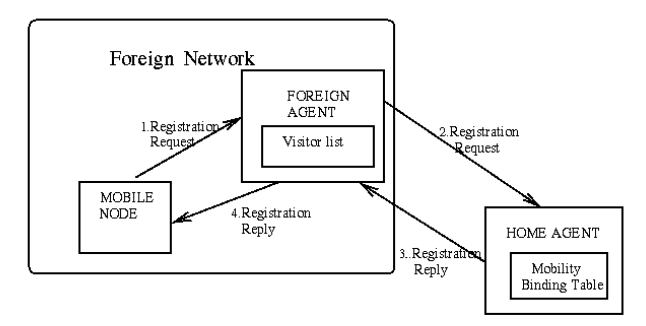
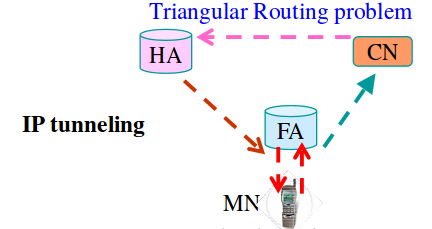
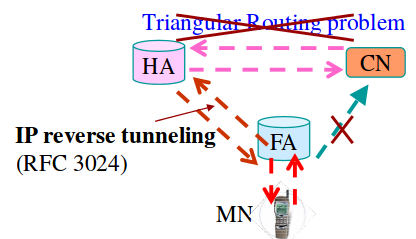
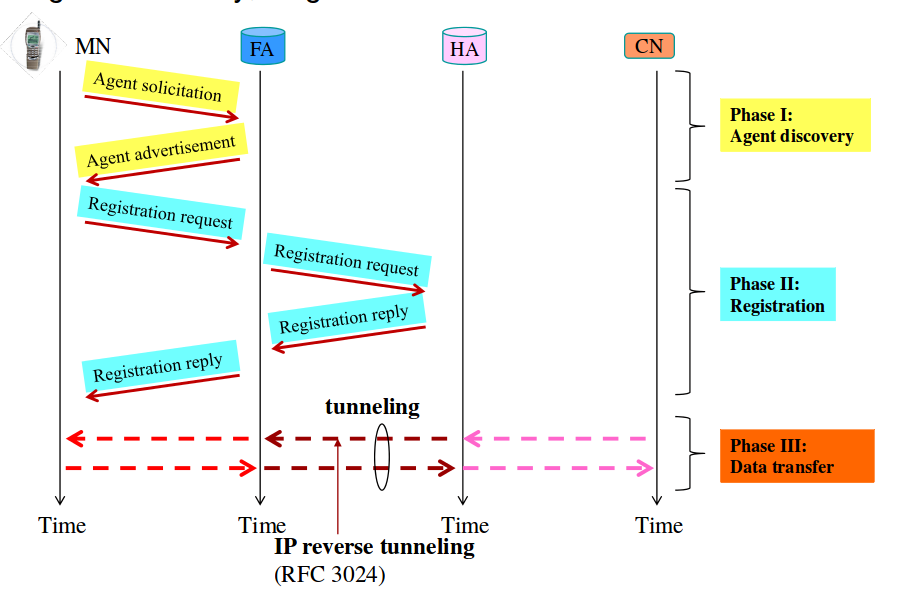
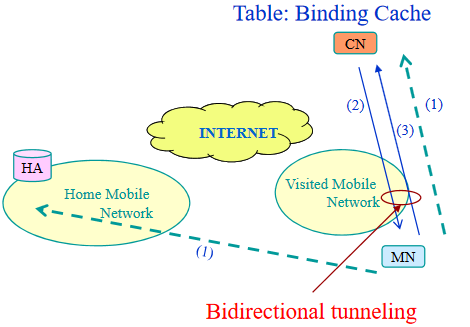
En las redes de transporte de Internet, para poder enviar grandes cantidades de información se utilizan unos protocolos especiales. Uno de ellos es SDH.
Synchronous Digital Hierarchy (SDH)
Una trama de SDH tiene una duración de 125 μs. Dentro de estos 125 μs se puede añadir información de muchos tributarios (usuarios). El número de tributarios que es posible añadir está estandarizado, de manera que las tasas binarias en SDH son:
| Tasa binaria SDH |
Interfaz óptico |
Tasa binaria |
| STM-1 |
OC-3 |
155 Mbps |
| STM-4 |
OC-12 |
622 Mbps |
| SMT-16 |
OC-48 |
2.5 Gbps |
| STM-64 |
OC-192 |
10 Gbps |
| STM-256 |
OC-768 |
40 Gbps |
Capas SDH
En el protocolo SDH existen 4 capas:
- Path Layer: establece conexiones end-to-end.
- Multiplex Section Layer: tareas de multiplexado, sincronización y protección.
- Regeneration Section Layer: genera las tramas y mantenimiento de la sección. Introduce o extrae los Virtual Containers.
- Photonic Layer: interfaz óptico por donde viaja la información
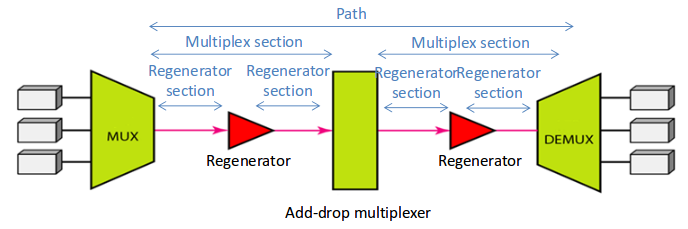 Las tramas de 125 μs están construidas por el contenedor básico llamado STM (Synchronous Transport Module), en el que cada uno equivale a 64 kbps.
Las tramas de 125 μs están construidas por el contenedor básico llamado STM (Synchronous Transport Module), en el que cada uno equivale a 64 kbps.
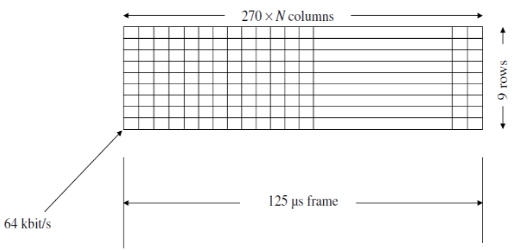
El STM-1 tiene una tasa binaria de:
\[270 \cdot 1 \cdot 9 \cdot 64~kbps = 155~Mbps\]
El STM-4:
\[270 \cdot 4 \cdot 9 \cdot 64~kbps = 622~kbps\]
La trama SDH está formada por la cabecera y la payload.
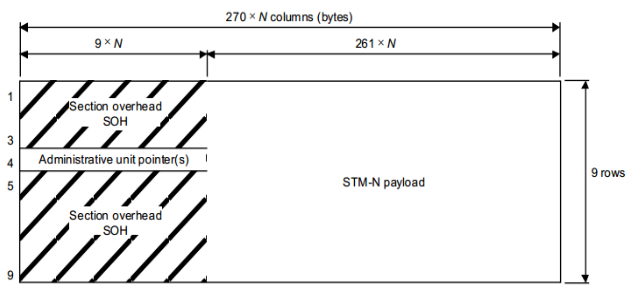
Cabecera
- Puntero con información de señalización y monitorización.
- Información APS (Automatic Protection Switching).
- Información sobre la estructura de la traba
Payload
También tiene una cabecera para señalización y medida de errores.
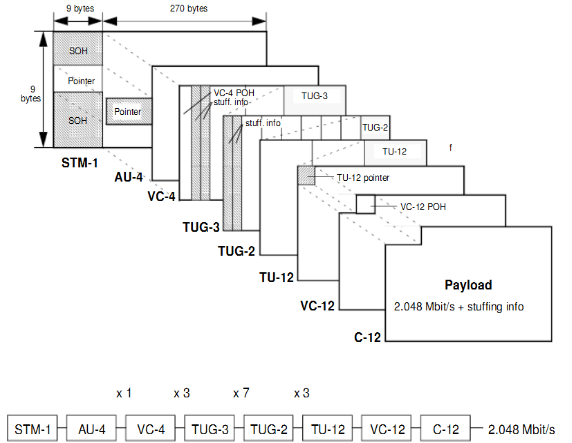
El container es la unidad básica de empaquetamiento.
Cabecera (llamada POH) + Container = Virtual Container
Los VC pueden ser de orden alto (alta velocidad) o de orden bajo (baja velocidad).
Hay containers de diferente tamaño que se tienen que encajar dentro del espacio de la payload (C2, C12, C11).
Los VC pueden ser creados por elementos no bien sincronizados, por lo que no se podrán añadir a tiempo dentro de la trama STM.
La cabecera estaba formada por un hueco llamado pointer. Este puntero se rellena con información que junto con un VC forma la unidad administrativa.
Todo el bloque de puntero + Todas las unidades administrativas = Grupo de unidad administrativa
¿Qué pasa con el tráfico de baja velocidad? ¿Cómo se puede poner dentro de la trama STM?
Con unidades tributarias = puntero + VC de bajo orden.
Varias unidades tributarias generan un grupo de unidades tributarias.
La unidad tributaria es igual que la unidad administrativa pero más pequeña. Son de VC de bajo orden.
Por orden de tamaño ascendente:
- Container
- Virtual container (VC): POH + C-n
- Unidad tributaria (TU): puntero + VC de bajo orden
- Unidad administrativa (AU): puntero + VC de alto orden
- Grupo de unidades tributarias (TUG): n · TU
- Grupo de unidades administrativas (AUG): n · AU
- STM-N: SOH + AUG
Generic Frame Procedure (GFP)
Para poder añadir información de diferentes protoclos (Ethernet, Fibre Channel, …) en una trama SDH se utiliza un procedimiento de entramado genérico. De esta manera SDH puede transportar cualquier protocolo sin importar su procedencia.
Concatenación SDH
Cuando se quiere transportar información mayor que la unidad básica, se pueden combinar varios contenedores. Por ejemplo añadir 599.04 Mbps utilizando 4 VC-4c. Sin embargo, de esta manera se desperdicia mucho espacio. Por eso, dos contenedores se enlazan mediante código y no físicamente contiguos. Esto se conoce como Virtual Concatenation Group (VCG).
Existe un método conocido como Link Capacity Adjustment Scheme (LCAS) que varía dinámicamente el ancho de banda de los contenedores de una concatenación virtual sin afectar al servicio.
Optical Transport Network (OTN)
Es un protocola (más bajo que SDH) para interconectar distintas redes de transporte. Al principio, cada fabricante lo hacía de manera diferente y por tanto no se podían interconectar entre sí.
| OTN |
Tasa binaria |
Equivalente SDH |
| OTU-1 |
2.5 Gbps |
STM-16 |
| OTU-2 |
10 Gbps |
STM-64 |
| OTU-3 |
40 Gbps |
STM-256 |
| OTU-4 |
100 Gbps |
– |
Esquemas de protección
En SDH, el tiempo máximo de recuperación por un fallo del sistema sin afectar al funcionamiento de este es de 60 ms: 50 ms para la conmutación de protección y 10 ms para detectar el fallo.
Conceptos básicos
Tipos de protección
- Protección dedicada: cada conexión activa tiene asignado su propio ancho de banda para reencaminar el tráfico en caso de fallo.
- Protección compartida: un ancho de banda de protección para múltiples conexiones activas.
También pueden considerarse:
- No reversibles: la conmutación de vuelta al camino activo original una vez se ha reparado un fallo es manual
- Reversibles: cuando se detecta que el falo ha sido reparado, se conmuta automáticamente a la fibra original.
Otras taxonomías:

a) Uso normal b) Unidireccional c) Bidireccional
Para notificar fallos en la red se utiliza el protocolo APS (Automatic Protection Switching).
Tipos de conmutación
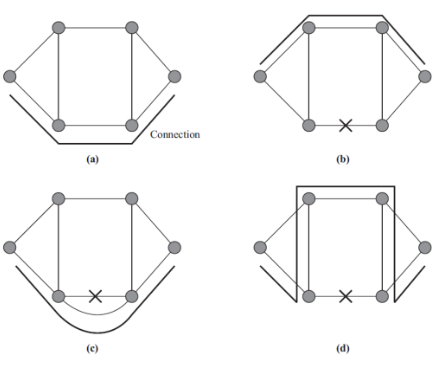
- Camino activo normal
- Conmutación de camino (path-switching): la conmutación de caminos se hace a nivel de path, de manera que la conexión se establece por un camino alternativo de punto a punto.
- Span protection: existe un camino replicado y paralelo al que ha dejado de funcionar.
- Conmutación de anillo. Solo se redirecciona en los nodos cuyo enlace no funciona. A diferencia del path-switching, este reencaminamiento no es punto a punto, sino que solo se da en el momento en el que el siguiente enlace no funciona.
1+1: el tráfico se transmite simultaneamente sobre dos fibras separadas.
1:1: hay 2 fibras pero el tráfico solo se envía por una. Se conmuta en caso de fallo y se notifica mediante APS (Automatic Protection Switching).
1:N: N fibras comparten un único camino de protección.
Anillos autoreparables, arquitecturas
SNCP: subnetwork connection protection
Anillo unidireccional. La fibra de protección se transmite en otro sentido. No necesita protocolo de señalización.
MS-SPRing: Multiplex Section Shared Protection Ring
El enrutamiento se realiza por el camino más corto. Hay 2 ó 4 fibras de protección.
Hay reutilización espacial: mientras la fibra auxiliar no falle, se puede aprovechar entre múltiples conexiones. Son anillos bidireccionales.
En MS-SPRing/4 hay 4 fibras. Si falla el enlace en una dirección hay una de reserva.
En MS-SPRing/2 hay 2 fibras. Cada una utiliza la mitad del ancho de banda. En caso de fallo todo el tráfico va por la otra (los dos sentidos de transmisión por la misma fibra).