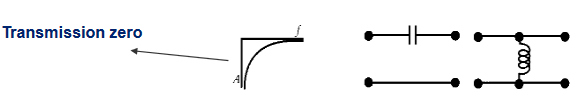\(\binom{n}{i}\) es el número de subconjuntos de \(i\) elementos que se puede hacer con un conjunto \(n\) elementos.
\(n\): número total de elementos
\(i\): longitud de los subconjuntos
\[\binom{n}{i} = \frac{n!}{i! \left( n-k \right)! }\]
Esto nos sirve también para poder entender el ensayo de Bernoulli. Este nos dice que si el resultado de un experimento ocurre con probabilidad \(k\) veces es:
\[P_n \left( k \right) = \binom{n}{k} P_A^k \left( 1-P_A \right)^{n-k}\]
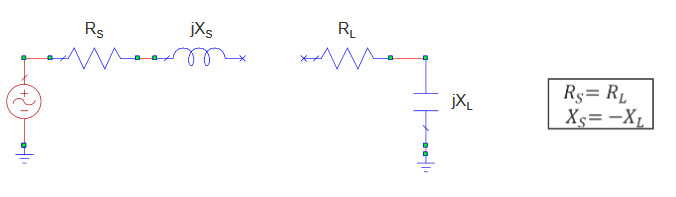
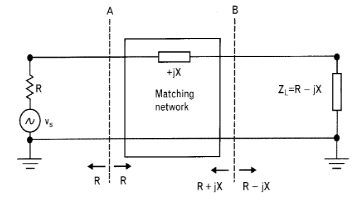
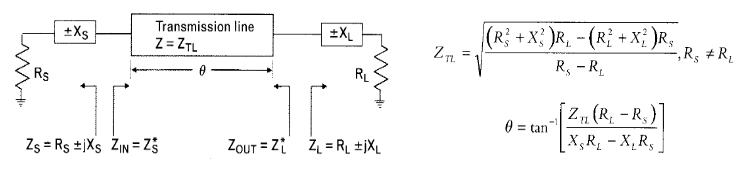
Las redes de adaptación son necesarias cuando queremos maximizar la transferencia de potencia entre dos sistemas conectados en cascada. Las redes de adaptación se comportan como filtros en los que en la banda de paso hay adaptación. En la banda de frecuencia a la cual la red no está adaptada, la potencia es reflejada.
Para asegurar la máxima transferencia de potencia, la impedancia de carga debe ser la compleja conjugada del generador.
Máxima transferencia de potencia (MTP)
Ceros de transmisión
Dependiendo de la disposición de inductores y condensadores, es posible crear ceros de transmisión en los cuales no haya transferencia de señal entre la entrada y la salida.
Cero de transmisión en DC ( \(f= 0\) ).
Para conseguir un cero de transmisión en DC podemos poner un condensador en serie entre entrada y salida o una inductancia en derivación (en paralelo a masa).
La pendiente con la que tiende a 0 el diagrama de Bode es de -20 dB/dec o 6 dB/oct.
Para calcular las octavas que hay entre dos frecuencias:
\[N_{octavas} = \log_2{\frac{f_{sup}}{f_{inf}}}\]
Para calcular el número de décadas entre dos frecuencias:
\[N_{dec} = \log_{10}{\frac{f_{sup}}{f_{inf}}}\]
Para pasar de décadas a octavas:
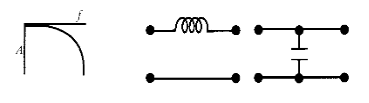
\[N_{dec} = 0.3 N_{octavas}\] Cero de transmisión en \(f=\infty\)
Para conseguir un cero de transmisión a frecuencias muy altas, hay que poner un inductor en serie o un condensador en derivación.
La pendiente en el diagrama de Bode es de 20 dB/dec o 6 dB/oct.
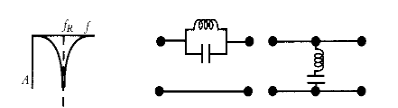
Cero a \(0< f_R < \infty\)
Para crear un cero a una frecuencia que no es ni DC ni a frecuencias infinitas, es necesario utilizar circuitos resonadores (también llamados circuitos tanque).
Existen dos tipos de resonadores: los serie y los paralelo.
Los resonadores serie constan de un condensador y un inductor en serie que a la frecuencia de resonancia equivalen a un cortocircuito. Por tanto, para forzar un cero de transmisión, será necesario poner un resonador serie en derivación.
Por otra parte, tenemos los resonadores paralelo, que a la frecuencia de resonancia son equivalentes a un circuito abierto. Para crear un cero de transmisión basta con ponerlos en serie entre la entrada y la salida del circuito.
La frecuencia de resonancia de un resonador es: \(f_R = \frac{1}{2\pi\sqrt{LC}}\)
Topologías de adaptación con elementos concentrados
Existen 3 topologías de redes en las que se necesita una red de adaptación para conseguir MTP:
\(R_s = R_L\)
\(R_s \neq R_L\)
La impedancia de carga o fuente es compleja.
1) Impedancia compleja con \(R_S = R_L\)
En esta red de adaptación el valor de la parte real de la impedancia coincide con la impedancia del generador. Sin embargo, hay un parte imaginaria que es necesario eliminar. En este caso es tan sencillo como añadir en serie una impedancia imaginaria de signo contrario. Es decir, si la reactancia es positiva (carácter inductivo), habrá que poner un condesador. Si la reactancia es negativa (carácter capacitivo), habrá que poner un inductor. De esta manera, es equivalente a tener un circuito tanque en serie. Sin embargo, como ya hemos visto anteriormente esta solución solo es válida para una frecuencia ya que ambos valores solo se anulan a su frecuencia de resonancia.
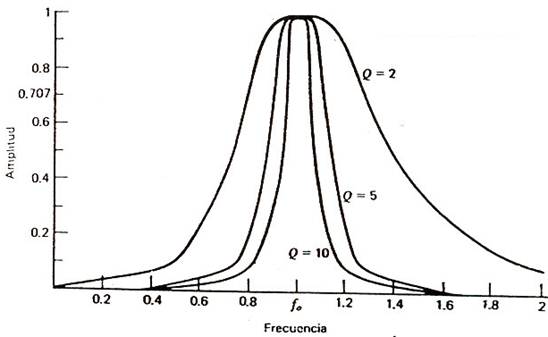
Una manera de medir cómo de estrecha será la banda a la cual se da la adaptación es utilizando el factor de calidad Q. En circuitos paso banda, el factor de calidad establece la relación que hay entre la frecuencia de paso y el ancho de banda a -3 dB. Es decir:
\[Q = \frac{f_0}{BW}\] Como vemos, si el ancho de banda es grande (poco selectivo), la Q es pequeña. Si el filtro es muy selectivo, la Q es grande.
Este parámetro puede ser medido en función de la reactancia y el valor de la resistencia de carga:
\[Q = \frac{X_L}{2R}\]
Por tanto, si la resistencia es grande la Q es pequeña (el filtro es poco selectivo) y la banda de adaptación es ancha. Si por el contrario la resistencia es pequeña lleva a Q muy grandes (muy selectivo). Ambos extremos son difíciles de solucionar en la práctica, ya que conseguir un filtro muy selectivo o de gran ancho de banda es complicado.
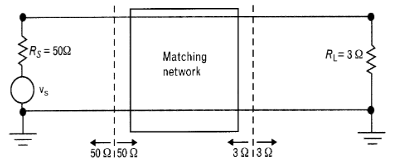
2) Impedancia compleja con \(R_S \neq R_L\)
En este caso, las resistencia de carga y de fuente no coinciden. Es por ello que se necesita subir o bajor el valor de la resistencia de carga para adaptar con la impedancia de fuente.
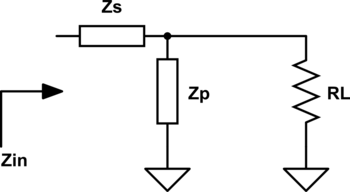
Para diseñar este tipo de redes de adaptación se utilizan redes en L:
Sin embargo el principal problema del diseño de este tipo de redes es que su cálculo es muy largo sobretodo cuando el número de elementos aumenta.
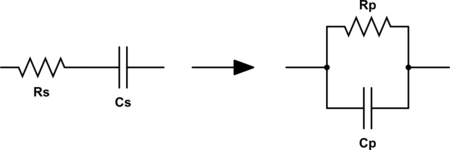
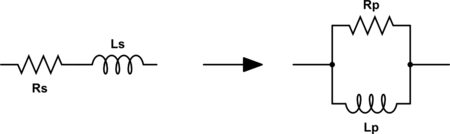
Este proceso se puede simplificar si utilizamos equivalencias serie-paralelo de circuitos RC y RL.
\[Q_s = \frac{X_s}{R_s} = Q_p = \frac{R_p}{X_p} = Q\]
\[R_p = \left( 1 + Q^2 \right)R_s\]
\[C_p \approx C_s\]
\[L_p \approx L_s\]
El factor de calidad (Q) indica cómo de ideal es un dispositivo a la hora de almacenar energía. Un dispositivo que pueda almacenar toda la energía sin disiparla tendrá un factor de calidad que tenderá a infinito. Una manera fácil de saber cómo es la expresión del factor de calidad con una resistencia en serie es pensando que si la resistencia en serie es muy grande, esta disipará mucha potencia y el factor de calidad será bajo. Por tanto, en la expresión del factor de calidad para un dispositivo con una resistencia en serie, el valor de la resistencia está en el denominador \(Q_p = \frac{R_p}{X_p}\)
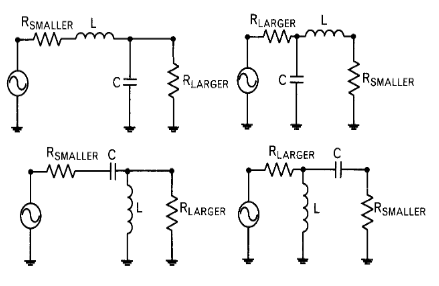
La manera en la que se deben colocar los elementos es la siguiente: con la resistencia de mayor valor, un elemento en paralelo (para bajar su impendancia). Y con la resistencia de menor valor un elemento en serie (para subir su impedancia).
Para calcular los valores de los elementos hay que igualar el factor de calidad Q de las redes serie y paralelo:
\[Q_s = Q_p = \sqrt{\frac{R}{r} – 1}\]
donde R es la resistencia con el valor nominal más alto y r la resistencia más baja.
Una vez calculado el factor de calidad, se obtiene el valor de la reactancia y con ello, el valor nominal del condensador o inductor.
Existen 4 disposiciones distintas:
Ejemplo:
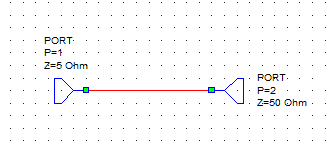
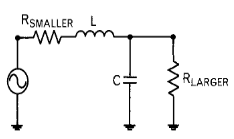
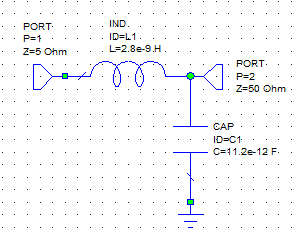
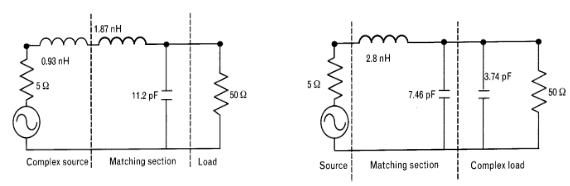
Queremos adaptar estos dos puertos para que a la frecuencia de 850 MHz haya MTP y al mismo tiempo que la polarización en DC también pueda pasar del puerto 1 al 2.
Debido a que no podemos bloquear la continua, no podemos utilizar un condensador en serie con la resistencia del puerto 1. Por tanto, tenemos que utilizar la red en L con una bobina en serie y un condensador en derivación:
Para calcular los valores de L y C:
\[Q_s = Q_p = \sqrt{\frac{R}{r} -1 } = \sqrt{\frac{50}{5} -1} = 3\]
\[Q_s = \frac{X_s}{R_s} \Rightarrow X_s = Q \cdot R_s = 2\pi f L\]
\[L = \frac{Q \cdot R_s}{2\pi f} = \frac{3 \cdot 5}{2\pi \cdot 850\cdot 10^6} = 2.8\text{ nH}\]
\[Q_p = \frac{R_p}{X_p} \Rightarrow X_p = \frac{R_p}{Q_p} = \frac{1}{2\pi f C}\]
\[C = \frac{Q_p}{2\pi f R_p} = 11.2\text{ pF}\]
Respuestra en frecuencia del parámetro S21
Sin embargo, cuando la diferencia de resistencias es muy grande, es posible que necesitemos unos valores de Q que no nos convengan en la práctica (recordar que \(Q = \sqrt{\frac{R}{r} – 1}\) ).
Es decir, este salto de impedancia puede ser muy grande
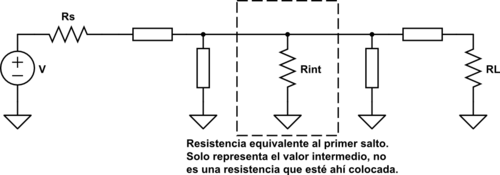
Podemos hacer varios saltos de impedancia en lugar de uno solo. Esto da lugar a las redes en T y redes en π:
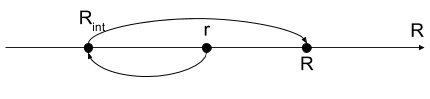
Por tanto disponemos de 3 tipos de redes: las redes en L, las redes en T y las redes en π. Con estas redes en T y π podemos aumentar el ancho de banda ya que al hacer saltos más pequeños de impedancia, la Q disminuye y el ancho de banda aumenta. Con las redes en L podemos disminuir el ancho de banda, ya que la resistencia virtual está entre un valor de \(R_{int} < r\) o \(R_{int} > R\).
Aumento del ancho de banda
Para aumentar el ancho de banda hay que utilizar una red en T o π. Si queremos una red de adaptación con un ancho de banda grande, la Q deberá se baja. Para que la Q sea baja, los saltos de impedancia deben de ser pequeños. Por tanto, podemos hacer saltos intermedios que tengan una Q menor y de esta manera aumentar el ancho de banda:
Para que una red en T o en π dé un ancho de banda mayor, el valor de la resistencia \(R_L\). Un valor adecuado es el que da la media geométrica entre los dos valores:
\[R_{int} = \sqrt{R_s R_L}\]
Por tanto, las redes en T y en π no sirven para adaptar resistencias de carga y generador ya iguales ya que se hacen saltos de impedancia.
Si queremos poner \(m\) sería:
\[R_m = R_S^{\frac{n-m}{n}} R_L^\frac{m}{n}\]
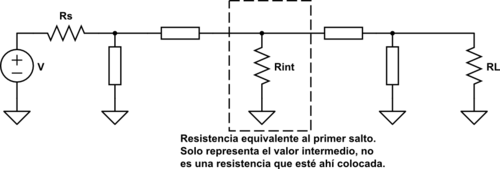
Reducción del ancho de banda
Para reducir el ancho de banda debemos hacer saltos de impedancia más grandes. Esto se puede conseguir de la siguiente manera:
El valor de \(R_{int} > R\). Ambas combinaciones harán que el ancho de banda sea menor.
3) Impedancias complejas
Una tercera forma de adaptar las impedancias de carga y fuente es mediante absorción o resonancia de la parte compleja de impedancia. Estas soluciones son de banda muy estrecha.
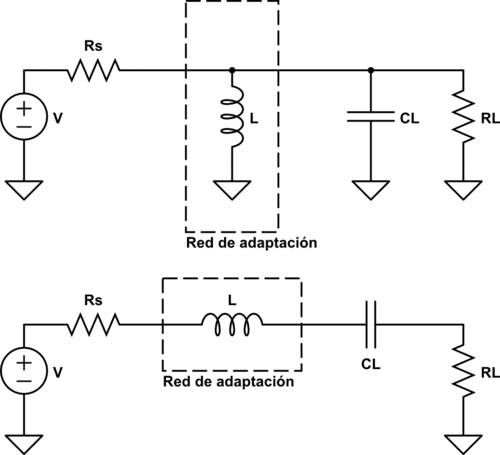
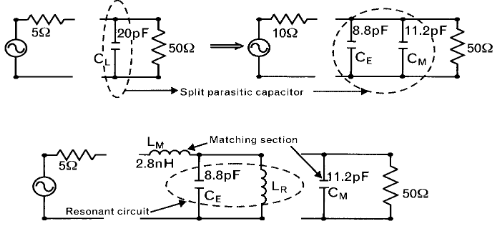
La absorción consiste en utilizar la parte compleja de la carga o fuente como parte de la red de adaptación. Es decir, si necesitamos un condensador de 10 pF y la carga tiene un condesandor equivalente de 5 pF, solo será necesario poner un condensador de 5 pF ya que los otros 5 pF restantes los pondrá la parte imaginaria de la impedancia de carga.
La otra estrategia es hacer resonar la reactancia de la carga para poder eliminarla a la frecuencia de trabajo. Es decir, si tenemos un condensador en derivación, podemos ponerle un inductor en paralelo para que resuene a la frecuencia de trabajo y haya máxima transferencia de potencia.
También podemos resonar solo una parte de la reactancia y utilizar la otra para conformar la red de adaptación en L:
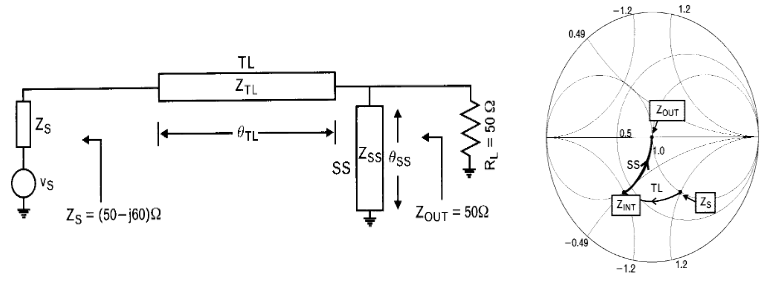
Adaptación con líneas de transmisión
En las líneas de transmisión tenemos 2 grados de libertad: la impedancia característica y la longitud eléctrica. Jugando con estos valores podemos sintetizar valores de inductancia y capacitancia utilizando transformadores en \(\frac{\lambda}{4}\) y stubs en paralelo. Sin embargo, las líneas de transmisión no sirven para adaptar los casos en los los valores de resistencia de carga y fuente sean diferentes.
El canal gaussiano se utiliza para modelar la amplia mayoría de casos reales en comunicaciones. A diferencia de los canales vistos anteriormente como el canal borrador o canal simétrico, el canal gaussiano es continuo. Este canal también es conocido como canal AWGN (Additive White Gaussian Noise Channel), en la que el ruido se modelo mediante una variable aleatoria gaussiana w, con media 0 y varianza \(\sigma^2\).
Una manera de poder detectar a la salida del canal los mensajes de la fuente, es mediante un detector por umbral.
Si transmitimos símbolos BPSK de amplitudes ±A, las funciones de verosimilitud \(p_y \left( y | x = A \right)\) y \(p_y \left( y | x = -A \right)\) son gaussianas de media ±A y varianza \(\sigma^2\)
Para decidir si se ha enviado un 1 ó un 0, se utiliza el criterio de mínima distancia, de manera que si los símbolos equiprobables basta con saber si están a la derecha o izquierda del origen de coordenadas para decirdir si son un 1 ó un 0 respectivamente.
Función Q
La función Q es una función que calcula la integral de una gaussiana, de manera que la podemos aprovechar aquí para calcular el error de símbolo en la función de distribución de probabilidad.
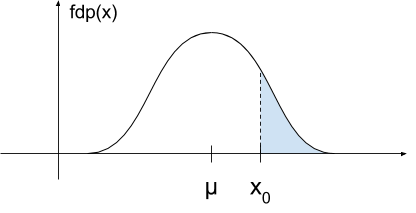
Si tenemos una función de probabilidad gaussiana con media \(\mu\), su expresión es:
\[p\left( x\right) = \frac{1}{\sigma \sqrt{2 \pi }}e^{-\frac{\left( x – \mu \right)^2}{2 \sigma^2}}\]
Si queremos saber la probabilidad que hay desde \(\mu + x_0\) hasta \(\infty\), la expresión utilizando la función Q es:
\[P\left( X > x_0 \right) = Q \left( \frac{ x_0 – \mu}{\sigma} \right)\]
De esta manera podemos calcular la probabilidad de error que se comete mediante el uso de detección por umbral:
\[P_e = Q \left( \frac{A}{\sigma} \right)\]
Hace algunas semanas compré por Ebay 3 módulos ESP8266 con la esperanza de poder utilizarlos en aplicaciones de IoT. Oí hablar de este módulo en Hackaday y solo leer de lo que era capaz no me lo pensé dos veces:
Procesador con puertos GPIO (General Purpose Input Output)
Wifi integrado
¡Solo vale 4€! (Actualización: actualmente es posible encontrarlo por ~1.5€)
Por tanto, este chip es capaz de conectarse con la red Wifi de tu casa, guardar o escribir información en una base de datos, hacer las veces de servidor, leer información de sensores, activar otros actuadores (como relés)… ¡Las posibilidades son enormes! Es un pequeñísimo Arduino con Wifi integrado.
Los primeros meses desde la salida del ESP8266 fueron bastante oscuros, ya que no se tenía apenas información, no había un SDK oficial y lo que había estaba en chino.
Pero recientemente la comunidad ESP8266 ha empezado a florecer ofreciendo diferentes vertientes por las que poder configurarlo. Yo me voy a centrar únicamente en la que utiliza el firmware NodeMCU.
Este firmware hace correr un compilador de LUA en el procesador, de manera que podremos escribir los programas que queramos correr en este mismo lenguaje.
Para poder instalar el firmware solo hay que conectar un FTDI (USB-UART converter) a nuestro ESP8266 de la siguiente manera:
Advertir que es obligatorio alimentar el ESP8266 a 3.3V, ya que por lo contrario quemaréis el chip.
Para entrar en modo de escritura de firmware hay que conectar el pin GPIO0 a masa. Yo he utilizado un jumper con que puedo conectar y desconectar fácilmente el pin.
Cuando tengamos este montaje hecho, necesitaremos descargar el grabador del firmware, que lo podemos encontrar también en el GitHub de NodeMCU.
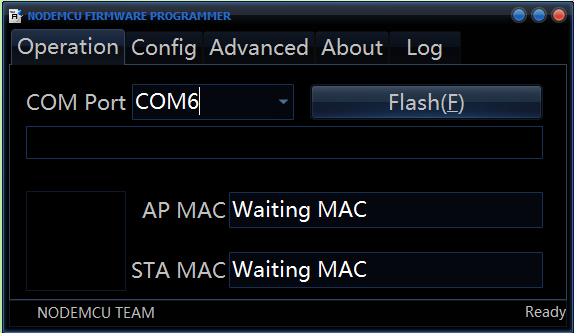
Una vez descargado, abrimos el flasher:
Con lo que nos aperecerá la siguiente aplicación:
Automáticamente cuando conectemos nuestro FTDI cambiará el puerto COM. Si no te sucede asegúrate de tener los drivers para tu FTDI instalados.
Flashear el ESP8266 con NodeMCU es tan sencillo como darle al botón Flash(F), y se pondrá a escribir el firmware en la memoria del procesador. Como se puede ver en la pestaña Config hace cuatro escrituras distintas, siendo la tercera la que más tiempo lleva. Cuando termine el FTDI se desconectará del equipo y aparecerá un símbolo verde abajo en la esquina izquierda. En mi caso dicho símbolo no ha aparecido pero el flasheo ha sido correcto igualmente.
Ahora que ya tenemos el firmware subido, tenemos que cargar nuestro programa. Para ello utilizaremos el programa LUAUploader de Hari Wiguna. Con esta aplicación especialmente desarrollada para el ESP8266 podremos subir nuestros programas de una manera muy sencilla.
Cabe destacar que la corriente que entrega un puerto USB del ordenador no es suficiente para iniciar el módulo de Wi-Fi, así que a partir de este momento es necesario alimentar el ESP8266 con una fuente externa. En mi caso he utilizado dos pilas LR03 (las pequeñas de los mandos) para obtener 3V. Recuerda que no sirven los 5V o el chip se quemará. Cuando conectes la fuente externa desconecta el pin de 3.3V del FTDI para evitar problemas, pero deja el pin de GND para unificar las masas del FTDI y de la fuente externa.
Una vez lo tengamos todo listo podemos pasar a lo divertido. Abrimos el LUAUploader y nos aparecerá la siguiente pantalla:
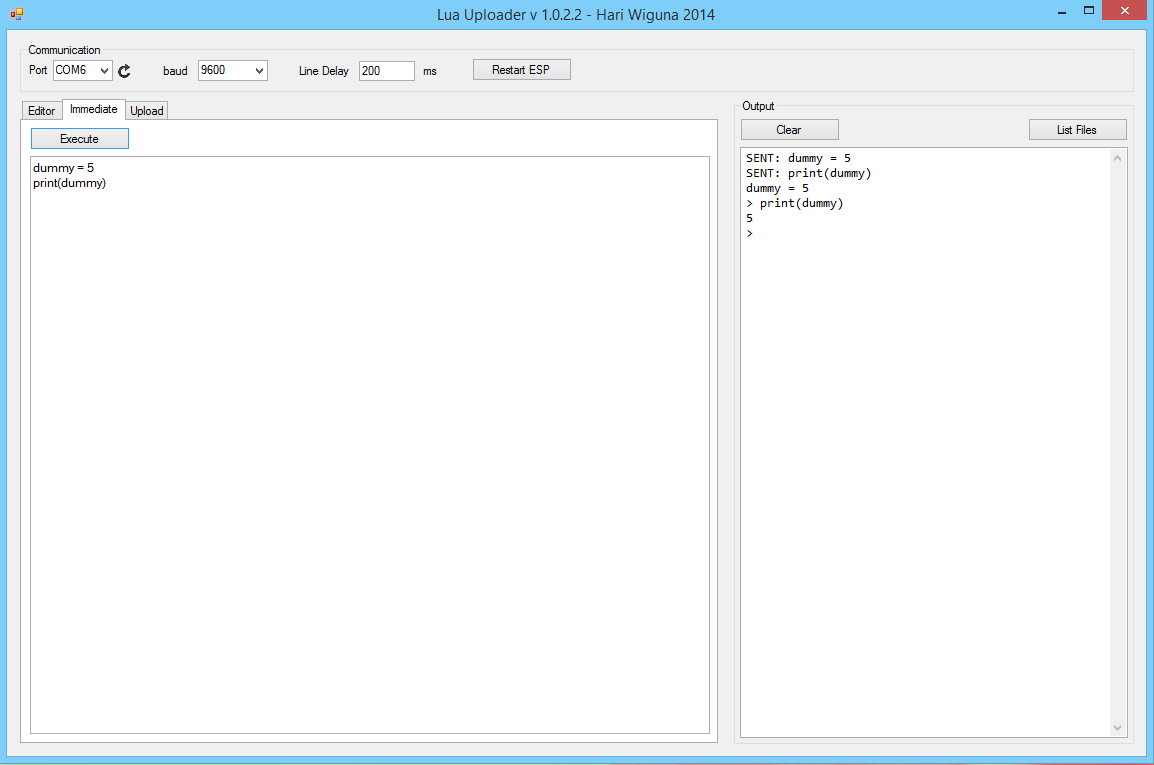
Para comprobar que el firmware ha sido grabado correctamente iremos a la pestaña “Immediate” y escribiremos un pequeño chunk de prueba (un chunk es cada trozo de código que Lua puede ejecutar)
dummy = 5
print(dummy)
Si el compilador nos devuelve 5, quiere decir que el firmware ha sido escrito correctamente:
Para poder conectarnos a nuestra red Wi-Fi es necesario introducir el siguiente chunk:
ip = wifi.sta.getip()
print(ip)
--nos devolverá nil
wifi.setmode(wifi.STATION)
wifi.sta.config("SSID","password")
ip = wifi.sta.getip()
print(ip)
--nos devolverá la IP asignada
Hay veces que después de intentar conectarse a la red Wi-Fi continúa devolviendo nil. Probad a imprimir de nuevo la dirección IP con:
ip = wifi.sta.getip()
print(ip)
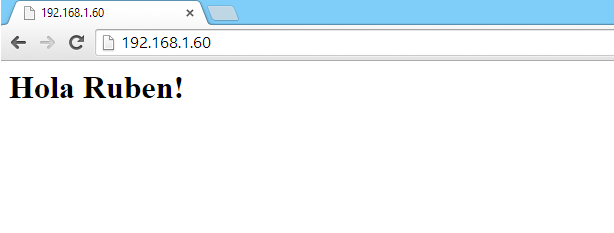
Ahora, para hacer una pequeña prueba, podemos montar un servidor en el propio ESP8266 con el chunk:
Una vez subido, si accedemos a la dirección del ESP8266 nos devolverá la página con un heading y el texto “Hola Ruben!” (para poder escribir acentos hay que utilizar los códigos ASCII en HTML y utilizar la columna HTML Número: é = é)
Para la creación de vídeo, cada píxel se guarda con 8 bits (valores de 0-255). Si se guarda de manera diferencial, los valores pueden ir de -255 a 255. Por tanto, necesitamos 9 bits para codificar cada píxel. La codificación diferencial se utiliza en vídeo porque en muchos casos, las diferencias entre fotograma y fotograma son pequeñas. De esta manera, si se codifica de manera diferencial, es posible ahorra bits. Sin embargo, si las diferencias suelen ser grandes, como ocurre en un cambio de escena, este tipo de codificación no es rentable.
Como en vídeo sí se utiliza codificación diferencial, es necesario intercalar fotogramas codificados de manera absoluta (llamados keyframes) para evitar que un error en un fotograma se propague hasta el final del vídeo. En vídeos que no se supone que se tienen que editar se coloca un keyframe cada 100~200 fotogramas, en TDT se coloca un keyframe cada 0.5 segundos y en vídeos para edición un keyframe cada 2~3 fotogramas.
Además, la información no es diferencial bit a bit, sino que utiliza el movimiento de una zona. Para detectar si el contenido de un fotograma está en el siguiente, se divide la imagen en bloques y se busca el grupo de píxels entero. Si el tamaño de estos bloques fuese muy pequeño, habría que informar del movimiento de muchos bloques, por lo que consumiría muchos bits. Es por ello que los bloques tienen un tamaño de 16×16 y se les llama macrobloques (MB). Sin embargo, para buscar el movimiento los saltos del MB no son de 16 en 16 sino que son más pequeños.
En MPEG-2 se definen 3 tipos de imagen:
Intra (I): tiene su información guardada en el propio frame por lo que no se codifica diferencialmente. Un error en I se propaga hasta la siguiente I ya que todo el resto de tipos, depende de su información.
Predicción (P): tiene una codificación diferencial, y su información solo puede estar referida a imágenes anteriores intra o otras también predictivas.
Bidireccional (B): utiliza información de referencia frames futuros y pasados de imágenes I, P o una imagen intermedia, pero nunca de otras B. Por tanto, un error en una imagen B no se propaga. La imagen intermedia es el calculo de la imagen media a partir de la referencia futura y la referencia pasada. Se guarda el menor error entre la media, la pasada y la futura. Para guardar la media, el codificador debe guardar los dos vectores de movimiento.
Por tanto, en la codificación y decodificación se necesita más memoria para almacenar las imágenes hasta que se satifagan las dependencias.
Demostrar que la información mutua es positiva \(I\left( X, Y \right) \geq 0\) y simétrica \(I \left( X, Y \right) = I \left( Y, X \right)\)
Para demostrar que la información mutua es positiva, tenemos que definir los valores de la información mutua entre dos símbolos. Para ello debemos tener en cuenta los valores extremos de \(P\left( x_i | y_j \right)\).
\(P\left( x_i | y_j \right) = 1\). Esta situación se da cuando tenemos un canal ideal sin ruido en el que si hemos recibido \(y_j\) es porque hemos enviado \(x_i\). De esta manera:
\[I \left( x_i, y_j \right) = \log{\frac{P \left( x_i | y_j \right)}{P\left( x_i \right)}} = \log{\frac{1}{P\left( x_i \right)}} = I \left( x_i \right)\]
En el otro extremo, tenemos cuando en el canal, la salida Y es independiente de X, por lo que es el peor canal que podemos tener. De esta manera, \(P\left( x_i | y_j \right) = P\left( x_i \right)\) por ser independientes.
\[I \left( x_i, y_j \right) = \log{\frac{P \left( x_i | y_j \right)}{P\left( x_i \right)}} = \log{\frac{P \left( x_i \right)}{P\left( x_i \right)}} = \log{1} = 0\]
Por tanto, queda demostrado que
\[0 \leq I \left( x_i, y_j \right) \leq I \left( x_i \right)\]
Por otra parte, queda demostrar que la información mutua es simétrica. Aplicando Bayes en la definición:
\[I \left( x_i, y_j \right) = \log{\frac{P \left( x_i | y_j \right)}{P\left( x_i \right)}} = \log{\frac{P \left( x_i , y_j \right)}{P\left( x_i \right) P\left( y_i \right)}} = \\ = \log{\frac{P \left( y_j | x_i \right) P\left( x_i \right)}{P\left( x_i \right) P\left( y_i \right)}} = \log{\frac{P \left( y_j | x_i \right) }{ P\left( y_i \right)}} = I \left( y_j, x_i \right)\]
Como hemos visto en la entrada anterior Concepto de la información, el término información nos da información sobre los posibles mensajes que una fuente puede producir. Sin embargo este término no es útil para describir a la fuente. Debido a que una fuente no está diseñada en torno a un solo mensaje, sino al conjunto de todos los mensajes que puede transmitir, podemos describir una fuente en términos de la información media producida. Esta información media transmitida se conoce como entropía de una fuente.
Si tenemos un alfabeto de longitud m \(X = \{ x_1, x_2, …, x_m \}\), la información del símbolo j es \(I_j = -\log{\frac{1}{P_j}}\). Si el número de símbolos enviados en el mensaje es \(N\), donde \(N >> 1\), el símbolo j se envía \(N \cdot P_j\) veces. Por tanto, la cantidad de información que se envía es:
\[ N P_1 I_1 + N P_2 I_2 + … + N P_m I_m = \sum_{i = 1}^{m}N P_i I_i~~~bits \]
La entropía de una fuente es el valor promedio de la información de cada uno de los símbolos de la fuente. Por tanto, si dividimos la expresion (\(\ref{eq:informacion_mensaje}\)) por el número de símbolos enviados \(N\), tenemos el valor medio en bits por símbolo:
Pero, ¿cuál es el significado de la entropía tal y como aparece en la ecuación de la entropía. Aunque no sepamos cuál es el siguiente símbolo que una fuente va a transmitir, en media podemos esperar conseguir \(H\) bits de información por símbolo o \(N\cdot H\) bits en un mensaje de N símbolos, si N es grande (mucho mayor que 1).
La entropía mide la cantidad de información que una fuente puede dar en un tiempo determinado
Rango de valores de la entropía de una fuente
De acuerdo, ya tenemos un parámetro para caracterizar una fuente. Veamos qué valores puede tomar este parámetro.
El mínimo de entropía se da cuando una fuente no da información. La fuente no tiene libertad de elección y siempre envía el mismo mensaje. Por tanto, la entropía es 0.
Por otra parte, la máxima entropía de una fuente se da cuando la fuente tiene máxima incerteza o lo que es lo mismo, máxima libertad de elección. Cada símbolo es igual de probable que el resto, por lo que \(P_j = \frac{1}{m}\) siendo \( m \) el número de símbolos. Así, \(\sum_{i=1}^{m}P_i I_i\) \(= \frac{1}{m} \log{\frac{1}{\frac{1}{m}}} \cdot m\) \(= \log{\frac{1}{\frac{1}{m}}} = \log{m}\).
De esta manera:
\[ 0 \leq H \leq \log{m} \]
Tasa de entropía
Ahora imaginemos que introducimos la variable de tiempo en la situación. Supongamos que tenemos dos fuentes con la misma entropía pero una es más rápida que la otra (i.e. enviando más símbolos por unidad de tiempo). De esta forma, la entropía no nos da ninguna información acerca de la velocidad con la que transmite la fuente. Es por ello que necesitamos de otro parámetro llamado tasa de entropía en la que informa de los bits enviados por segundo.
\[ R = \frac{H}{\bar{\tau}} \]
donde \( \bar{ \tau } \) es la duración media por símbolo que se define como
\[ \bar{\tau} = \sum_{j=1}^{m} P_i \tau_i \]
y que \( 1/ \bar{\tau}\) equivale al número medio de símbolos por unidad de tiempo.
Tasa de transmisión: 14 Mb/s
Ancho de banda: 5 MHz
\(\left.P_{Tx}\right|_{EB} = 43~dBm\)
Factor de ruido del receptor: \(\left.F\right|_{Rx} = 4~dB\)
Frecuencia de la portadora \(f_c = 900~MHz\)
Ganancia del transmisor: \(G_{Tx} = 15~dB\)
Ganancia del terminal de usuario: \(G_{UE} = 0~dB\)
Modelo a utilizar:
– \(f_c = 900~MHz\)
– Altura de la antena transmisora: \(h_{EB} = 15~m\) sobre edificios
De las pérdidas de propagación también podemos extraer el parámetro \(\gamma\) ya que \(10\gamma\) es el número que multiplica el término \(\log{R}\).
\(\gamma = 3.76\)
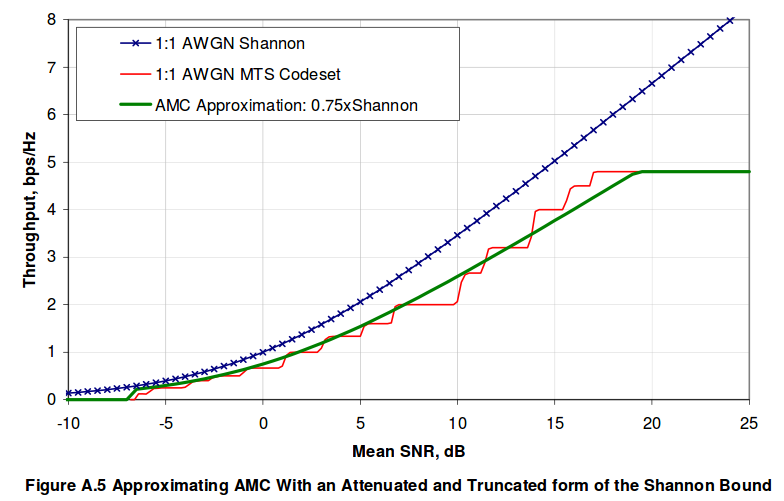
De la gráfica podemos ver que la SINR(dB) equivalente es aproximadamente 11 dB. También podemos sacarlo de la fórmula del límite de Shannon corregida \(\eta = \frac{C}{B} = 0.75 \log_2{(1+SNR)}\)
\[SINR(dB) = 11dB\]
\[SINR(dB) < CINR(dB)\]
Uno de los casos más complicados y que engloban todas las posibles dificultades en el cálculo de la polarización es en el caso de tener una onda plana que no se propaga según los ejes.
Primero vamos a comenzar por recordar cómo se pueden clasificar las diferentes polarizaciones de onda electromagnética.
Polarización lineal: la onda electromagnética se propaga variando su amplitud en una línea.
Polarización circular: la onda electromagnética dibuja una circunferencia.
Polarización elíptica: la onda electromagnética se propaga dibujando una elipse.
Para averiguar con qué polarización se propaga una onda electromagnética se tienen que satisfacer las siguientes condiciones:
Polarización lineal: se da cuando una de las dos componentes perpendiculares es nula o cuando el desfase entre ambas es múltiplo de \(\pi\) (\(0\), \(\pi\), \(2\pi\), …).
Polarización circular: la onda electromagnética tiene dos componentes de la misma amplitud y se encuentran desfasadas un multiplo entero de \(\frac{\pi}{2}\), por lo que la onda electromagnética. Si \(\phi_2 – \phi_1 > 0\) se trata de polarización circular a izquierdas (o levogira) mientras que si \(\phi_2 – \phi_1 < 0\) se trata de polarización circular a derechas (o dextrogira).
Polarización elíptica: no se satisfacen ninguno de los requisitos anteriores.
Algoritmo general de análisis de polarización
Definir vector unitario del sentido de propagación \(\hat{\mathbf{k}}\): es el vector que acompaña la exponencial compleja cambiado de signo.
Escoger una base unitaria en la que descomponer la amplitud \(\mathbf{e_1}\). Para calcular la polarización, hay que escribir la amplitud de la onda electromagnética en dos vectores perpendiculares al vector de propagación. Por tanto, podemos escoger cualquier vector que sepamos que sea perpendicular al vector \(\hat{\mathbf{k}}\).
Calcular la base perpendicular a \(\hat{\mathbf{k}}\) y \(\mathbf{e_1}\). Para ello hay que realizar el producto vectorial \(\hat{\mathbf{k}} \times \mathbf{e_1}\).
Descomponer la amplitud del campo en las bases \(\mathbf{e_1}\) y \(\mathbf{e_2}\) en forma compleja polar. Es tan sencillo como hacer el producto escalar de la amplitud por el vector unitario de ambas bases.
Dividir el módulo de \(E_{01}\) entre \(E_{02}\) y restar \(\phi_2 – \phi_1 \) y verificar a qué caso de polarización pertenece.
Comprobar las condiciones: \(\frac{E_{02}}{E_{01}} = \frac{\sqrt{42}}{\sqrt{6}} \approx 2.64\), \(\phi_2 – \phi_1 = 0.33 + \frac{\pi}{6} \approx 0.8565\) Como no se satisface ninguna de las condiciones para polarización lineal ni circular, se trata de una polarización elíptica a izquierdas (diferencia de fases positiva).
Por fin podemos hablar de el primer proyecto más o menos serio que he hecho con ESP8266 y esta vez se trata de un medidor de nivel agua con los datos guardados en la nube, de manera que sean accesibles desde cualquier sitio.
Principios de funcionamiento
Para empezar, imaginemos que tenemos una cisterna donde tenemos agua. Primero debemos asumir que las medidas de la cisterna se mantienen constantes en todo momento, esto es, ancho, largo y alto. Para conocer el volumen de agua que reside en el interior tan solo necesitaremos saber cuál es la altura del agua, ya que es la única variable del sistema.
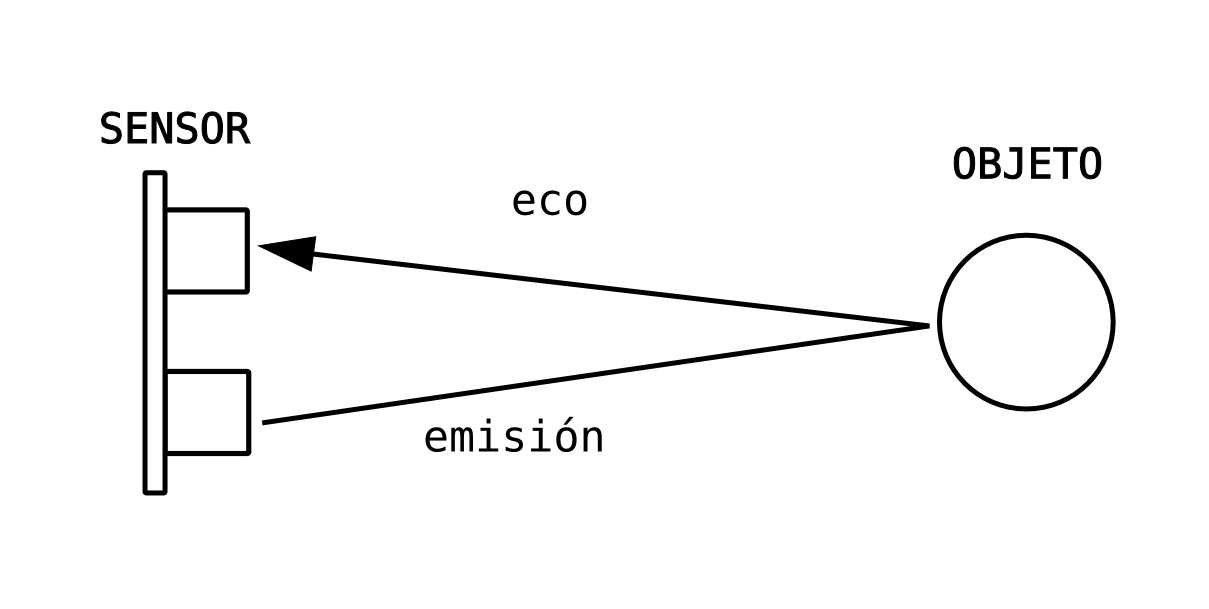
Con esto claro, necesitamos un mecanismo que sea capaz de medir a qué altura de encuentra el agua. Mi idea ha sido utilizar un sensor ultrasónico, cuyo funcionamiento es el siguiente:
El altavoz emite un sonido de frecuencia ultrasónica (imperceptible al oido humano)
Se pone un cronómetro en marcha.
El micrófono recibe la señal que había sido emitida por el altavoz.
Se para el cronómetro que se había puesto en marcha al emitir el sonido
Se calcula sabiendo la velocidad del sonido, la distancia a la que está el objeto sobre el cual ha rebotado la pulsación ultrasónica.
Materiales
Para empezar los materiales que he utilizado son:
ESP-01 (ESP8266)
Fuente de alimentación de 3.3V
Fuente de alimentación de 5V
Programador FTDI
Sensor ultrasónico HC-SR04
Montaje hardware
El módulo ultrasónico HC-SR04 tiene 4 pines:
Vdd: debemos conectar 5V. No podemos conectar directamente los 3.3V con los que alimentamos el ESP-01. Una lástima.
Trig: es el encargado de dar la orden al altavoz de que emita el pulso.
Echo: es el micrófono que espera el rebote del pulso emitido.
GND: es importante unificar la masa del ESP-01 con la propia de la fuente de 5V para evitar problemas de grounding.
En mi caso he utilizado los 5V que tiene disponible el Arduino, aunque es algo bastante engorroso. Para la versión final, utilizaré un convertidor lineal (para conseguir los 3.3V) y una sola alimentación.
La conexión entre el ESP-01 y el HC-SR04 es extremadamente sencilla:
GPIO0 – Echo
GPIO2 – Trig
Software
Para hacer funcionar el HC-SR04 con NodeMCU, he utilizado el código que ha subido sza2 en GitHub modificándolo un poco.
Se trata de dos archivos: init.lua y hcsr04.lua. Cabe destacar que el ESP8266 ejecuta init.lua en cuanto se enchufa. La base de su funcionamiento reside en el uso de la función tmr.alarm(), que ejecuta una función cada intervalo de tiempo que nosotros definamos. En este caso, la función de medir distancia.
El código de sza2 envía vía serie el resultado cada 0,5s, pero podemos configurarlo como nosotros queramos. Solo recordar que hay que introducir el tiempo en milisegundos.
En el código original se imprime por pantalla el resultado, pero como hemos dicho anteriormente nuestro objetivo es que la lectura sea subida a un servidor para poder ver el nivel de agua desde cualquier sitio.
Para ello he utilizado una plataforma llamada ThingSpeak, que sirve precisamente para esto. Su funcionamiento es muy sencillo. La información se guarda en los que ThingSpeak llama canales. En cada canal podemos añadir hasta 8 variables que queramos monitorizar, y la manera en que podemos guardar nuevos datos es haciendo una petición HTTP con el método GET. Las variables que tenemos que incluir en la petición HTTP es el código del canal (para saber dónde hay que guardar la información), el número del campo a guardar seguido del valor.
De esta manera quedará registrado automáticamente en ThingSpeak, como podemos ver en este applet:
También decir que el HC-SR04 devuelve valores contiguos que difieren unos de otros por motivos obvios, por lo que he modificado el código para que devuelva el valor medio de 500 medidas.
El código completo del archivo init.lua es:
dofile("hcsr04.lua")
wifi.setmode(wifi.STATION)
wifi.sta.config("SSID","pass")
print(wifi.sta.getip())
device = hcsr04.init()
print("Loading...")
function send(value)
if value ~= -1 then
print(value)
conn=net.createConnection(net.TCP, 0)
conn:on("receive", function(conn, payload) print(payload) end)
conn:connect(80,'184.106.153.149')
conn:send("GET /update?key=CodigoAPI&field1="..value.." HTTP/1.1\r\n")
conn:send("Host: api.thingspeak.com\r\n")
conn:send("Accept: */*\r\n")
conn:send("User-Agent: Mozilla/4.0 (compatible;ESP8266; Windows NT 5.1)\r\n")
conn:send("\r\n")
end
end
tmr.alarm(0, 60000, 1, function() send(device.measure()) end)
hcsr04 = {};
function hcsr04.init(pin_trig, pin_echo)
local self = {}
self.time_start = 0
self.time_end = 0
self.trig = pin_trig or 4
self.echo = pin_echo or 3
gpio.mode(self.trig, gpio.OUTPUT)
gpio.mode(self.echo, gpio.INT)
function self.echo_cb(level)
if level == 1 then
self.time_start = tmr.now()
gpio.trig(self.echo, "down")
else
self.time_end = tmr.now()
end
end
function self.measure()
medidas = 500
mean = 0
for i=1,medidas,1 do
gpio.trig(self.echo, "up", self.echo_cb)
gpio.write(self.trig, gpio.HIGH)
tmr.delay(100)
gpio.write(self.trig, gpio.LOW)
tmr.delay(100000)
if (self.time_end - self.time_start) < 0 then
return -1
end
mean = mean + (self.time_end - self.time_start) / 58
end
print(mean/medidas)
return mean/medidas
end
return self
end