Basic operation
The left hand side of the keyboard uses a Microchip MCP23018 IC, which is an I/O expander with open drain outputs and it can be configured through I2C or SPI. In this case we are going to focus on the I2C protocol only since it is the one used by the main MCU. The MCU is a Teensy 2.0 and it is placed on the right hand side of the Ergodox. It is used for monitoring all the switch status, converting the pressed switches into its corresponding character and sending it through USB to interact with the computer as a usual keyboard.
The MCP23018 has two different GPIO ports, GPIOA and GPIOB, each with 8 I/O pads. In the original Ergodox PCB, port A is used to interact with the columns and port B with the rows.
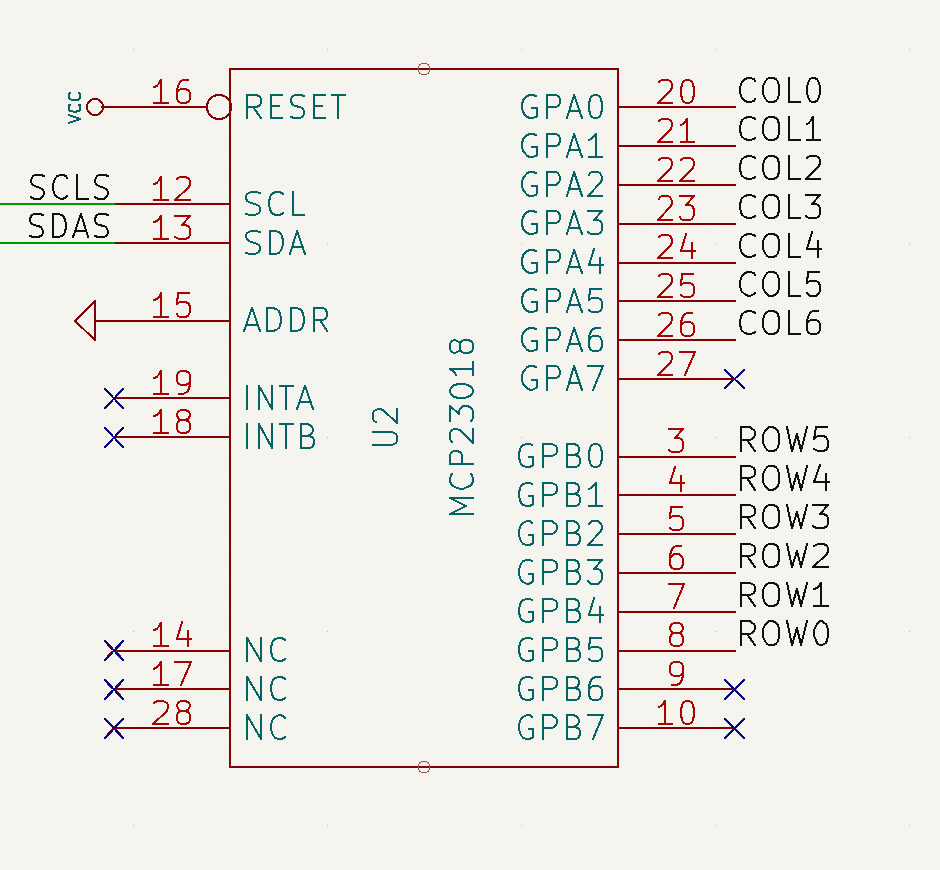 GPIO pads on port B (rows) are configured as inputs and the internal pull-up resistor is enabled on every port B pad. Regarding GPIO pads on port A, they are configured as outputs. According to the datasheet, output pads on the MCP23018 are open-drain, which basically means that the pad value can be internally driven to ground or left floating (high impedance). Since the rows and columns are connected through the mechanical switch and the diode, GPIO’s on port B can determine if the switch is closed (pressed) or open (released) depending on the voltage found at it. A diagram of this scheme is shown below.
GPIO pads on port B (rows) are configured as inputs and the internal pull-up resistor is enabled on every port B pad. Regarding GPIO pads on port A, they are configured as outputs. According to the datasheet, output pads on the MCP23018 are open-drain, which basically means that the pad value can be internally driven to ground or left floating (high impedance). Since the rows and columns are connected through the mechanical switch and the diode, GPIO’s on port B can determine if the switch is closed (pressed) or open (released) depending on the voltage found at it. A diagram of this scheme is shown below.
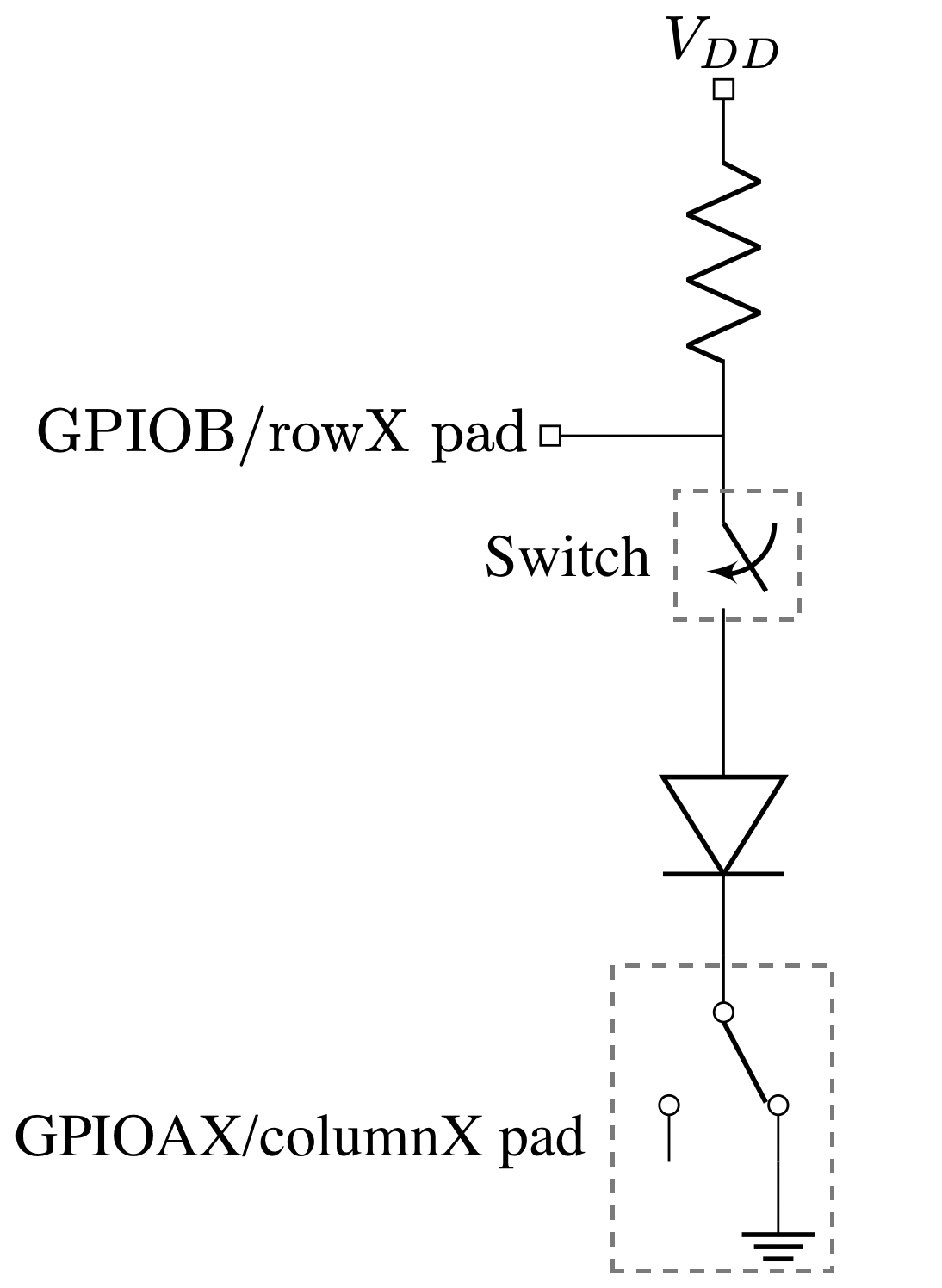
The way the Ergodox firmware determines the state of every switch (closed/pressed or open/released) is by sequentially setting one column to ground while leaving the rest floating. Then, the state of the rows is read. Depending on the state of the switch, the GPIOB reading will be:
- If the switch is released, the voltage at GPIOB will be VDD due to its pull-up resistor. The pad value will be read as 1.
- If the switch is closed, the voltage at GPIOB will be set to 0.0 V. The pad value will be read as 0.
Since the rest of columns are left floating, they won’t interfere on the reading. Once the state of a particular row is read, its value is stored and the operation is repeated until all the available rows are covered. The process of reading the state of all the switches is called a «scan».
Debugging MCP23018 with Arduino
When I assembled my Ergodox, I loaded the QMK firmware expecting the keyboard to just work. However, there seems to be a hardware issue since the comunication between the LHS and the RHS is not successful. Therefore, I decided to replicated the QMK firmware on an Arduino to have a better understanding on how the MCP and the Teensy interact together and also figure out if there’s really any hardware issue on the PCB’s.
QMK firmware is highly customizable and therefore it can be a little bit intricate when trying to read its code. I tried to distil the most basic functionality regarding the writing and reading done from the Teensy to the Mcp23018 through I2C.
The code below will perform a scan every 1 second and will print through the Serial interface the keyboard matrix result.
mcp23018_debug.c
#include <Wire.h>
#include "mcp23018.h"
#include "i2c_wrapper.h"
#include "utils.h"
#define KB_ROWS 6
#define KB_COLUMNS 7 // 14 in total, 7 in left hand side
int data;
bool matrix[KB_ROWS][KB_COLUMNS];
void setup() {
Wire.begin();
Serial.begin(9600);
while (!Serial); // Leonardo: wait for Serial Monitor
Serial.println("\nMCP23018 debugger");
delay(2000);
mcp23018_init();
}
void loop() {
while(true) {
// Clear matrix values
clear_matrix();
for (uint8_t col = 0; col < KB_COLUMNS; col++) {
// Drive column to ground
drive_column(col);
// Read GPIO's on port B
data = i2c_rd(I2C_ADDR, GPIOB);
for (uint8_t row=0; row < KB_ROWS; row++) {
// Store read values into the matrix
matrix[row][col] = !( data & (1<<(5-row)) );
}
}
print_matrix();
// Leave column floating again
drive_column_hiz();
// Wait 1 second
delay(1000);
}
}
void drive_column(uint8_t col) {
i2c_wr(I2C_ADDR, GPIOA, 0xFF & ~(1 << col));
}
void drive_column_hiz() {
i2c_wr(I2C_ADDR, GPIOA, 0xFF);
}
void clear_matrix() {
for (uint8_t row = 0; row < KB_ROWS; row++) {
for (uint8_t col = 0; col < KB_COLUMNS; col++) {
matrix[row][col] = 0;
}
}
}
void print_matrix() {
for (uint8_t col = 0; col < KB_COLUMNS; col++) {
if (col == 0) {
Serial.println("[ ");
}
for (uint8_t row = 0; row < KB_ROWS; row++) {
Serial.print(matrix[row][col] ? 1 : 0);
Serial.print(" ");
}
Serial.println();
if (col == 6) {
Serial.println("]");
}
}
}Output:
MCP23018 debugger
[
0 0 0 0 0 0
0 0 0 0 1 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
]
where 1 means the switch is pressed and 0 released.
Auxiliary files
i2c_wrapper.h
#include <Wire.h>
int i2c_rd(int i2c_addr, int reg_addr) {
int rd_data;
// Start condition + 7 bit I2C device address
Wire.beginTransmission(i2c_addr);
// Write bit + next byte
Wire.write(reg_addr);
// Stop condition
Wire.endTransmission();
// Start condition + address + read bit
Wire.requestFrom(i2c_addr, 1); // request 1 byte from slave device
if(Wire.available()) {
rd_data = Wire.read();
}
Wire.endTransmission();
return rd_data;
}
int i2c_wr(int i2c_addr, int reg_addr, uint8_t wr_data) {
// Start condition + 7 bit I2C device address
Wire.beginTransmission(I2C_ADDR);
// Byte with address to be written
Wire.write(reg_addr);
// Data to be written
Wire.write(wr_data);
// Stop condition
return Wire.endTransmission();
}mcp23018.h
#define I2C_ADDR 0b0100000
// i/o direction register
#define IODIRA 0x00
#define IODIRB 0x01
// GPIO pull-up resistor register
#define GPPUA 0x0C
#define GPPUB 0x0D
// general purpose i/o port register (write modifies OLAT)
#define GPIOA 0x12
#define GPIOB 0x13utils.h
#ifndef _UINT8_T
#define _UINT8_T
typedef unsigned char uint8_t;
#endif /* _UINT8_T */
int print_addr_val(int addr, int val) {
Serial.print("Addr ");
Serial.print(addr, HEX);
Serial.print(": ");
Serial.println(val, BIN);
}