La decodificación MAP es aquella en la que se decide qué símbolo ha sido transmitido en función de la probabilidad a posteriori, es decir \(P\left(x_i | y_j \right)\) o la probabilidad condicional de que si se ha recibido \(y_j\), se haya transmitido \(x_i\). Dicho de otro modo, ¿cuál es el símbolo más probable que la fuente haya podido enviar \(x_i\) si yo he recibido \(y_j\)? Aquel de todos los posibles símbolos que se hayan podido transmitir cuya probabilidad a posteriori sea máxima, será el que se decida como transmitido.
\[hat{x}_i = \max{ \{ P\left( x_i | y_j \right) \} }\]
Pero sin embargo, para poder determinar esta probabilidad, al decodificador se le tiene que pasar la información del canal. En lugar de recibir del canal directamente si se ha enviado un 1 ó un 0 (salida hard), el decodificador tiene como entrada la información del espacio de la señal, es decir, con el valor analógico de la salida del canal. De esta manera el decodificador dispone de mayor información para tomar la decisión de cuál ha sido el código transmitido. Este valor representa una medida de la fiabilidad con la que es tomado cada símbolo y se conoce como un codificador con entrada soft.
Un modo de calcular estas probabilidades a posteriori de manera computacionalmente eficiente, es mediante el algoritmo BCJR (ideado por Bahl, Cocke, Jelinek y Raviv en el 1974). El algoritmo BCJR permite la obtenención de las LLR a posteriori (Log Likelihood Ratio) por bit (\(x_i\) binario):
\[LLR \left( x_i | y \right) = \ln{\frac{P \left( x_i = 1 | y \right) }{P \left( x_i = 0 | y \right)}}\]
Mediante el uso de la LLR, si la probabilidad de haber transmitido \(x_i = 1\) habiendo recibido y es mayor que la de haber transmitido \(x_i = 0\), el valor del logaritmo es positivo y negativo al contrario. Por eso, es más sencillo mirar el signo de la operación, que comparar directamente el valor absoluto de los dos valores.
A diferencia del algoritmo de Viterbi, el BCJR calcula de manera diferente cuál ha sido el bit más probable que se ha podido transmitir. Viterbi calculaba decisiones hard a partir de la detección de la secuencia de símbolos más probable, es decir, aquella que supusiera un recorrido cuya distancia a través del Trellis fuera de menor distancia. Sin embargo, el algoritmo BCJR calcula información soft. Por tanto, mientras que el algoritmo de Viterbi produce la secuencia de símbolos más probable que minimiza la probabilidad de error por secuencia, el algoritmo BCJR minimiza la tasa de error media por símbolo. Esta sutil diferencia hace que la detección de códigos mediante BCJR sea más ventajosa que utilizando el algoritmo de Viterbi.
Ambos algoritmos comparten similitudes ya que ambos están basados en el mismo diagrama de Trellis, ambos asignan una métrica a cada transición y ambos recorren el diagrama de trellis recursivamente. Sin embargo, en lugar de pasar de principio a final como hace Viterbi, en el algoritmo BCJR se realizan dos pasadas: de izquierda a derecha y de derecha a izquierda.
Revisando el diagrama de trellis
Imaginemos que estamos en la etapa i de un diagrama de trellis cualquiera tal y como aparece en la figura. En el diagrama de trellis podemos definir el dato que entrega el canal como \(y_i\). El estado antes de la transición como \(S_{i-1}\) y el diagrama después de la transición como \(S_i\).
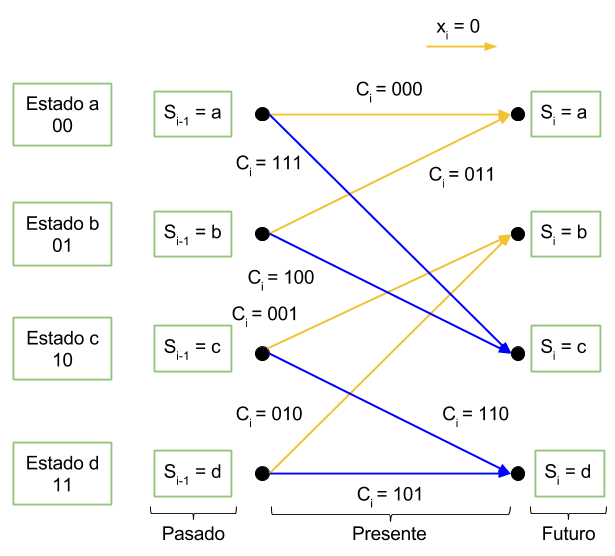 La clave del algoritmo BCJR es la descomposición de la probabilidad a posteriori para una transición en tres factores: el primero dependiendo de las observaciones pasadas, el segundo dependiendo de observaciones presentes y el tercero atendiendo a observaciones futuras. Cabe destacar que cuando se aplica el algoritmo BCJR el receptor ya dispone de la trama completa de datos, por lo que es posible separar entre pasado, presente y futuro. Es decir, dado un bit en la posición i, el algoritmo sí tiene acceso a los bits que se enviaron después de él. No es un algoritmo que se aplica al vuelo conforme llegan bits.
La clave del algoritmo BCJR es la descomposición de la probabilidad a posteriori para una transición en tres factores: el primero dependiendo de las observaciones pasadas, el segundo dependiendo de observaciones presentes y el tercero atendiendo a observaciones futuras. Cabe destacar que cuando se aplica el algoritmo BCJR el receptor ya dispone de la trama completa de datos, por lo que es posible separar entre pasado, presente y futuro. Es decir, dado un bit en la posición i, el algoritmo sí tiene acceso a los bits que se enviaron después de él. No es un algoritmo que se aplica al vuelo conforme llegan bits.
La decodificación de un símbolo mediante el criterio MAP viene dada por:
\[hat{x}_i = \max_{x_i \in \left \{ \text{M simbolos} \right \} }{ \{ P\left( x_i | y \right) \}} = \left \{ \text{Teorema de Bayes} \right \} = \\ \max_{x_i \in \left \{ \text{M simbolos} \right \} }{ \frac{ p \left( x_i, y \right) }{ p \left( y \right) } } = \left \{ p \left( y \right) \text{ constante} \right \} = \\ \max_{x_i \in \left \{ \text{M simbolos} \right \} }{ \{ p \left( x_i, y \right) \} } = \max_{l \in \left \{ 0, 1, …, M -1 \right \} }{\sum_{\left( S_{i-1}, S_i \right) \in S^l } p\left( S_{i-1}, S_i, y \right) } donde l \in \left \{ 0, 1, …, M -1 \right \}\]
son todos los posibles símbolos \(y \left( S_{i-1}, S_i \right) \in S^l\) son las posibles transiciones que salen de cada estado cuando se envía el símbolo l. Por ejemplo, en una comunicación binario los únicos símbolos son 0 y 1 (es decir \(l \in \left \{ 0, 1 \right \}\) que en este caso se llaman bits). Por tanto, de cada estado que tenga el decodificador saldrán dos posibles transiciones. Una debida a la recepción del bit 0 y otra al bit 1. El conjunto de transiciones que ocurren cuando se recibe un 0 se denominan \(S^0\) y las transiciones que ocurren cuando al decodificador entra un 1 se denominan \(S^1\).
Por tanto, de la ecuación \(\ref{eq:limite}\) podemos interpretar que para estimar el símbolo \(\hat{x}_i\) con mayor probabilidad de haber sido enviado, hay que encontrar la suma de las probabilidades conjuntas de estar en el estado \(S_{i-1}\), ir al estado \(S_i\) y haber recibido los datos y para cada uno de los símbolos. Aquel símbolo que de una suma mayor, será el elegido como \(\hat{x}_i\).
Como hemos dicho antes, podemos descomponer el diagrama de estados en tres: pasado, presente y futuro. De este modo, los datos recibidos y se pueden descomponer como los datos recibidos en el pasado, el bit recibido en el presente y los bits que me llegarán en el futuro.
\(\mathbf{y}=\left [ \left ( y_1~y_2~…~y_{i-1} \right ), y_i, \left (y_{i+1}~y_{i+2}~…~y_{N} \right ) \right ] = \left[ \mathbf{y}_1^{i-1}, y_i, \mathbf{y}_{i+1}^N \right] \) donde \(\mathbf{y}_1^{i-1}\) representa a los datos recibidos en el pasado, \(y_i\) es el dato que recibo en el presente y \(\mathbf{y}_{i+1}^N\) son los datos que recibiré en el futuro. El subíndice 1 indica pasado, el i indica presente y el i+1 indica futuro. Así mismo, el superíndice i-1 indica la dimensión del vector. En el caso de los datos pasados el vector tendrá una dimensión desde 1 hasta i-1 (por tanto dimensión i-1). Para el caso de los datos futuros, la dimensión va desde i+1 hasta N, que es el número de símbolos enviados (o bits si la señal es binaria).
Ahora, a partir de la interpretación que hemos hecho arriba de la función densidad de probabilidad \(p\left( S_{i-1}, S_i, y \right)\), podemos aplicar el teorema de Bayes repetidas veces para conseguir una función equivalente pero separada en varios trozos.
A modo de recordatorio:
\[p\left( a, b \right) = p \left(a | b\right) p \left( b \right)\]
\[p\left( a, b, c \right) = p \left(a | b, c\right) p \left( b, c \right)\]
\[p\left( a, b, c, d \right) = p \left(a, b | c, d\right) p \left(c, d \right)\]
Teniendo en cuenta esto, podemos reescribir la función \(p\left( S_{i-1}, S_i, y \right)\) como, \(p\left( S_{i-1}, S_i, \mathbf{y} \right) = p \left( S_{i-1}, S_i, \mathbf{y}_1^{i-1}, y_i, \mathbf{y}_{i+1}^N \right)= p \left(\mathbf{y}_{i+1}^N | S_{i-1}, S_i, \mathbf{y}_1^{i-1}, y_i \right) p \left( S_{i-1}, S_i, \mathbf{y}_1^{i-1}, y_i \right) \)
En \(\ref{eq:prob_states_1}\) hemos descompuesto los datos recibidos en pasado, presente y futuro. Después hemos escrito la misma función utilizando la probabilidad condicionada de los datos futuros \(\mathbf{y}_{i+1}^N\). Ahora volvemos a aplicar la probabilidad condicionada en el factor \(p \left( S_{i-1}, S_i, \mathbf{y}_1^{i-1}, y_i \right)\) pero esta vez evaluando la expresión a llegar al estado \(S_i\) y que el dato sea \(y_i\) si estábamos en el estado \(S_{i-1}\) y los datos pasados son \(y_1^{i-1}\). \(p \left(\mathbf{y}_{i+1}^N | S_{i-1}, S_i, \mathbf{y}_1^{i-1}, y_i \right) p \left( S_{i-1}, S_i, \mathbf{y}_1^{i-1}, y_i \right) = \\ p \left(\mathbf{y}_{i+1}^N | S_{i-1}, S_i, \mathbf{y}_1^{i-1}, y_i \right) p \left(S_i, y_i | S_{i-1}, \mathbf{y}_1^{i-1} \right)p \left(S_{i-1}, \mathbf{y}_1^{i-1} \right)\)
Ahora fijémonos en cada término: \(p \left(S_{i-1}, \mathbf{y}_1^{i-1} \right)\): es la probabilidad conjunta de haber estado en el estado \(S_{i-1}\) y que los datos anteriores fueran \(\mathbf{y}_1^{i-1}\). A esta expresión la vamos a llamar \(\alpha_{i-1} \left( S_{i-1} \right)\).
\(p \left(S_i, y_i | S_{i-1}, \mathbf{y}_1^{i-1} \right)\): es la probabilidad de llegar al estado \(S_i\) con el símbolo \(y_i\) sabiendo que estábamos en el estado \(S_{i-1}\) y que se habían enviado anteriormente \(y_1^{i-1}\). Obviamente, los datos que se habían enviado anteriormente no van a afectar en dónde estaré posteriormente si ya sé que estaba en \(S_{i-1}\). Una analogía fácil para visualizar este hecho es el siguiente: yo estoy en el punto A. Desde este punto tengo dos caminos que puedo elegir: el camino 1 y el camino 0. Para determinar si voy a terminar en el punto B o no, me da exactamente igual saber qué camino escogí para llegar al punto A. Solo me importa donde estoy, dónde voy y qué caminos tengo para elegir en ese momento. Por tanto, la expresión \(p \left(S_i, y_i | S_{i-1}, \mathbf{y}_1^{i-1} \right)\) se puede simplificar como \(p \left(S_i, y_i | S_{i-1}\right)\). A esta expresión la vamos a llamar \(\gamma_{i} \left( S_{i-1}, S_i \right)\).
\(p \left(\mathbf{y}_{i+1}^N | S_{i-1}, S_i, \mathbf{y}_1^{i-1}, y_i \right)\): siguiendo la analogía anterior, esta expresión representa cuál es la probabilidad de que escoja en el futuro una serie de caminos si ya sé dónde estoy, dónde estuve anteriormente, los caminos que escogí en el pasado y el camino que he cogido para llegar a dónde estoy ahora mismo. En este caso, poco importa saber dónde estuve hace tiempo, saber cómo llegué allí o cómo he llegado a donde estoy, ya que solo saber dónde estoy ahora mismo (\(S_i\)) me da información de adónde puedo ir \(\mathbf{y}_{i+1}^N\), cuáles serán los bits que me pueden llegar en el futuro). Por tanto, esta expresión la podemos simplificar como \(p \left(\mathbf{y}_{i+1}^N | S_{i-1}, S_i, \mathbf{y}_1^{i-1}, y_i \right) = p \left(\mathbf{y}_{i+1}^N | S_i, y_i \right)\). A esta expresión la vamos a llamar \( \beta_{i} \left( S_{i} \right)\).
De esta forma podemos redefinir el diagrama de trellis como muestra la siguiente figura.
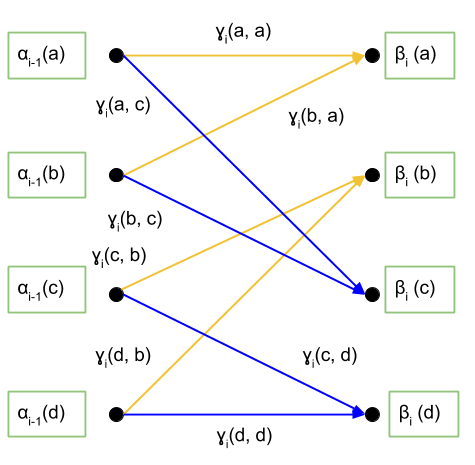
Así podemos calcular cuanto valdría P\left( x_i = 0 | \mathbf{y}\right):
\[P\left( x_i = 0 | \mathbf{y}\right) = \sum_{\left( S_{i-1}, S_i \right ) \in S^0}{p\left( S_{i-1}, S_i, \mathbf{y} \right )} = \\ = \sum_{\left( S_{i-1}, S_i \right ) \in S^0}{\alpha_{i-1}\left(S_{i-1} \right) \gamma_i \left(S_{i-1}, S_i \right ) \beta_i \left(S_i \right )} = \\ =\alpha_{i-1}\left(a \right ) \gamma_i \left(a, a \right ) \beta_i \left(a \right ) + \alpha_{i-1}\left(b \right ) \gamma_i \left(b, a \right ) \beta_i \left(a \right ) + \\ + \alpha_{i-1}\left(c \right ) \gamma_i \left(c, b \right ) \beta_i \left(b \right )+ \alpha_{i-1}\left(d \right ) \gamma_i \left(d, b \right ) \beta_i \left(b \right )\]
Para calcular \(P\left( x_i = 1 | \mathbf{y}\right)\) sería igual pero utilizando las otras transiciones. O también \(P\left( x_i = 1 | \mathbf{y}\right) = 1 – P\left( x_i = 0 | \mathbf{y}\right)\)
Cálculo de α
\[\alpha_i \left( S_i \right) = p \left(S_i, y_1^i \right ) =\sum_{S_{i-1}, S_i \in S}{p \left(S_{i-1}, S_i, \mathbf{y}_1^{i-1}, y_i \right)} = \\ = \sum_{S_{i-1}, S_i \in S}{p \left( S_i, y_i| S_{i-1}, \mathbf{y}_1^{i-1} \right)}p \left(S_{i-1}, \mathbf{y}_1^{i-1} \right) = \\ = \sum_{S_{i-1}, S_i \in S}{p \left( S_i, y_i| S_{i-1} \right )}\alpha_{i-1} \left(S_{i-1} \right) = \sum_{S_{i-1}, S_i \in S}{\alpha_{i-1} \left( S_i \right)}\gamma_{i} \left(S_{i-1}, S_i \right)\]
Donde \(1 \leq i \leq N\) y \(N\) el número de símbolos enviados. Como vemos es un cálculo recursivo, en el que necesitamos el valor del α anterior para calcular el siguiente.
Cálculo de β
\[\beta_{i-1} \left(S_{i-1} \right ) = p \left(\mathbf{y}_i^n |S_{i-1} \right ) = \sum_{S_{i-1}, S_i \in S}{p \left( y_i,\mathbf{y}_{i+1}^n, S_i |S_{i-1}\right )}= \\ =\sum_{S_{i-1}, S_i \in S}{p \left(\mathbf{y}_{i+1}^n | S_i, y_i, S_{i-1}\right ) p \left( S_i, y_i| S_{i-1}\right )} =\\=\sum_{S_{i-1}, S_i \in S}{p \left(\mathbf{y}_{i+1}^n | S_i\right ) p \left( S_i, y_i| S_{i-1}\right )} =\sum_{S_{i-1}, S_i \in S}{\beta \left(S_i\right ) \gamma_i\left( S_{i-1}, S_i\right )}\]
Cálculo de γ
\[\gamma_i \left(S_{i-1}, S_i \right ) = p \left(S_i, y_i | S_{i-1} \right ) =p \left(y_i | S_i, S_{i-1} \right ) p \left(S_i | S_{i-1} \right) = p \left(y_i | c_i \right ) p \left( x_i \right )\]
Como podemos ver y era de esperar, el parámetro \(\gamma\) depende del canal, ya que \(p \left(y_i | c_i \right )\) es la función de verosimilitud que caracteriza el canal. En caso de ser un canal gaussiano, la \(p \left(y_i | c_i \right ) = \frac{1}{\sigma^2 \sqrt{\pi}} \cdot e^{- \frac{\left| y_i – c_i \right|^2}{2\sigma^2} }\)